학습 날짜: 2025.08.13 ~ 2025.08.14
어제부터는 빅데이터 분석을 위한 통계 공부를 시작했다. 나는 학부와 석사 과정에서 심리 통계 수업을 세 차례 수강한 경험이 있기에, 내용 자체는 낯설지 않았다. 그러나 통계학에서 사용하는 관점과 용어가 내가 익혀 온 것과 미묘하게 달라, 오히려 익숙했던 개념들이 혼란스럽게 느껴지는 순간도 있었다. 그래서 이번에는 헷갈리지 않도록, 이해한 내용을 정리하는 데 초점을 두었다.
개요
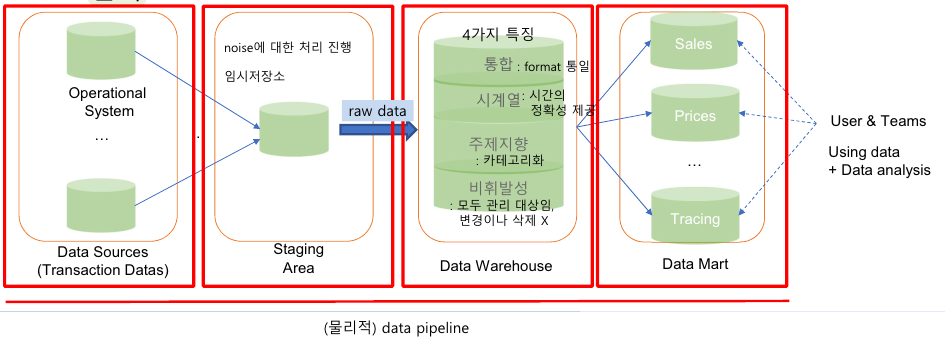
데이터 처리 흐름
- 데이터웨어하우스(Data Warehouse, DW): 비즈니스 전체 데이터셋을 포함하는 중앙 데이터 저장소
- 데이터마켓(Data Marget, DM): 최종 사용자가 쉽게 조회할 수 있도록 비즈니스 기능에 따라 데이터를 분리 및 데이터큐브 생성
데이터 분석 기법 종류
- 시각화
: 데이터를 가장 쉽게 분석할 수 있는 방법 - 공간분석(QGIS)
: 지도 위에 데이터 특성을 나타내는 방법 - 탐색적 자료 분석(EDA)
: 연속형 또는 문자형 데이터들의 시각화를 통해 해당 변수의 분포 또는 관계 및 특징을 찾아내는 방법 - 통계분석
- 기술통계: 모집단으로부터 표본을 추출하고 기초통계량으로 데이터 분석
- 추론통계: 기초통계량으로 모집단의 특징을 추정(추론)하는 데이터 분석
- 데이터 마이닝(= ML, DL)
: 대량의 데이터에서 의미있는 정보를 추출하는 개념
: 새로운 상관관계, 패턴 등을 탐색하고 모형화하여 미래에 대한 예측을 하는 방법
모집단과 표본
- 모집단(population)
: 분석이 필요한 관심 대상의 전체 집합 - 모수(parameter)
: 모집단을 분석하여 얻어지는 결과 수치(수량적 특성)
예) 평균(μ), 분산(σ²), 표준편차(σ) - 표본(sample)
: 모집단의 하위 집단으로 실질적인 데이터 분석의 대상 - 통계량(statistic)
: 표본을 분석하여 얻어지는 하나의 값으로 나타내어지는 결과 수치(수량적 특성)
예) 평균(x̄), 분산(s²), 표준편차(s)
- 표집(sampling)
: 모집단(Population)에서 일부를 선택해 표본(Sample)을 만드는 절차 또는 방법
: 표본은 모집단을 완벽히 대표하지 못할 수 있어 표집 오차가 발생 - 추론(Inference)
: 통계량에 기반하여 모수치 값을 추측하는 과정
: 적절한 표본 설계와 분석 방법을 통해 오차를 줄이는 것이 목표
표본 추출(표집) 방법
- simple random sampling (단순 무선 표집)
- 모집단에 대해 무작위 추출, 선택될 확률이 동일한 표집 방법
- 난수표를 사용하기도 함
- 장점: 연구자의 편견이 들어갈 가능성 낮음
- 단점: 항상 모집단을 대표하지 않을 수 있음
- stratified random sampling (층화 표집)
- 모집단을 몇 개의 층으로 나누고, 각 층의 데이터 비율만큼 단순 무선 표집을 진행
- imbalanced dataset에 사용 가능
- 장점: 표집 오차를 줄일 수 있음
- 단점: 층을 나누기 위해 모집단의 특성을 알아야 하고 계층을 정의하는 변수가 적절치 못할 가능성이 있음
- systematic sampling (쳬계적 표집, 계통추출법)
- 모집단 목록에서 매 k번째 요소를 표본으로 선정하는 방법
- 장점: 표본 추출이 용이, 적은 비용
- 단점: 데이터가 패턴을 가지게 되는 경우 모집단의 특성을 하나도 반영하지 못할 수 있음
- cluster sampling (군집 표집)
- 모집단의 구성요소가 군집화 되어 있는 경우, 군집을 표본 단위로 하여 무작위 추출
- 단, 군집간 동질성 & 군집내 이질성이 확보되어야 함
- 장점: 모집단에 일부만 알면 가능함
- 단점: 표집오차가 클 수 있음, 군집이 모집단을 대표하지 못할 수 있음
표본데이터 형태
데이터 표현 용어 이해
아래와 같이 행렬 형태 또는 스프레드시트 형태로 변환하여 데이터 분석에 사용

- 변수(Variable | Feature)
: 측정 가능한 속성, 머신러닝에서 Feature 라고 함
예) sepal.length, sepal.width, petal.length, petal.width, species - 관측값(Value | Feature Value)
: 샘플링 시 변화됨
예) setosa, versicolor, virginica - 관측점(observation | row | instance)
: 측정된 정보 집합
예) [row 1] 0 | 4.9 | 3.0 | 1.4 | 0.2 | setosa
데이터 척도 종류 이해
- 범주형(Categorical) → 이산형, 질적 데이터
- 명목척도(Nominal)
: 순서 없음, 예) 성별, 혈액형, 직업 구분, 지역 구분 - 서열척도(Ordinal)
: 순서 있음, 예) 만족도, 학점, 계급
- 명목척도(Nominal)
- 연속형(Continuous) → 수치형, 양적 데이터
- 구간척도(Interval)
: 측정치 간의 간격이 일정, 덧셈·뺄셈 가능
: 절대 '0' 없음 (0은 기준점)
예) 온도 - 비율척도(Ratio)
: 절대 '0' 있음
: 사칙연산 모두 가능
예) 신장, 매출액, 소득, 시청률, 교통사고 건수
- 구간척도(Interval)
확률 및 분포
용어정리
확률? 어떤 사건이 발생할 가능성을 0~1사이의 숫자로 표현한 것
- 확률 실험(= 결과가 랜덤한 실험) ⇒ 확률모형
↓
- 표본 공간
↓
- 사건 (= 표본 공간의 부분집합)
확률의 공리
- 임의의 사건A에 대해 P(A) ≥ 0
- P(S) = 1
- 표본공간 S에 정의된 서로 상호배반인사건 A1, A2, A3...에 대해 P(A1 ∪ A2 ∪ A3 ...)
상호배반적이다 = 교집합이 없다.
즉, 한 사건의 결과에 대해 공존할 수 없으면 상호배반이임.
예) 주사위를 한 번 던졌을 때,
- 사건(A): 짝수
- 사건(B): 홀수
⇒ A와 B는 동시에 발생할 수 없으므로 상호배반
확률 종류 (베이즈 정리 관점)

| 확률 종류 | 정의 | 기호 | 예시 |
| 사전 확률 (Prior Probability) |
사건 A가 발생할 가능성, 정보(B) 없이 추정한 확률 | P(A) | 비 예보를 보기 전, 계절과 날씨 패턴에 기반해 비가 올 확률 |
| 사후 확률 (Posterior Probability) |
사건 B가 일어난 이후 A가 발생할 확률 | P(A∣B) | 비가 올 확률을 기상 레이더 데이터(증거)를 기반으로 갱신한 값 |
| 조건부 확률 (Conditional Probability) |
특정 조건하에서 다른 사건이 발생할 확률 | P(B∣A) |
비가 오는 날에 우산을 쓸 확률 |
| 결합 확률 (Joint Probability) |
두 사건이 동시에 발생할 확률 | P(A ∩ B), P(A,B) |
비가 오고 동시에 기온이 30도 이상일 확률 |
| 주변 확률 (Marginal Probability) |
다른 사건과 관계없이 단독으로 일어날 확률 | P(B) | 기온과 상관없이 비가 올 확률 |
조건부 확률
표본공간 S에 사건 A와 B가 정의되어 있으며, P(B) > 0라고 가정
이 때, 사건 B가 일어났다는 가정하에 사건 A가 일어날 조건부 확률은
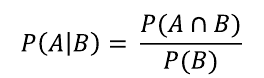
예) 사건 A: 주사위 눈이 3이하, 사건 B: 짝수 ⇒ P(A | B) = 3/6
독립 사건
? 두 사건이 서로의 발생 확률에 영향을 주지 않는 경우
두 사건 A, B가 다음 중 하나를 만족하면 서로 독립
1) P(A | B) = P(A)
2) P(A ∩ B) = P(A) P(B)
3) P(B | A) = P(B)
상호배반과 독립의 차이
| 구분 | 상호배반(Mutually Exclusive) | 독립(Independent) |
| 정의 | 두 사건이 동시에 발생할 수 없음 | 한 사건이 다른 사건의 발생 확률에 영향을 주지 않음 |
| 수학식 | P(A ∩ B) = 0 | P(A ∩ B) = P(A) P(B) |
| 동시 발생 여부 | 절대 불가능 | 가능 |
| 영향 여부 | 한 사건이 발생하면 다른 사건은 반드시 발생 불가 | 한 사건의 발생 여부가 다른 사건의 확률에 영향을 주지 않음 |
| 예시 | 주사위 1회 던짐 → 짝수/홀수 | 동전 2회 던짐 → 첫 번째 앞면, 두 번째 앞면 |
| 관계 | 상호배반이면 보통 독립이 아님* | 독립이어도 상호배반일 필요 없음 |
확률변수(Random Variable)
확률 실험의 결과를 숫자로 대응시키는 함수
즉, 결과값 자체가 아니라 결과를 숫자값으로 매핑해 주는 규칙
데이터프레임과 연결해서 보면 각 컬럼(column)은 "하나의 확률 변수"처럼 생각 가능
예: height, weight, score 컬럼 → 각각 다른 확률 변수
[ 종류 ]
- 이산확률변수: 확률변수가 취할 수 있는 값의 개수가 유한
- 연속확률변수: 확률변수가 취할 수 있는 값의 개수가 무한

'LG U+ Why Not SW Camp 8기 > 학습 로그' 카테고리의 다른 글
| 공부 일지 #22 | 데이터 분석 기초 정리2: 자유도, 분포, 기초통계량 (3) | 2025.08.18 |
|---|---|
| 공부 일지 #21 | Python Pandas 기본 문법 정리: 데이터 전처리 기초 (8) | 2025.08.14 |
| 공부 일지 #19 | SQL Toy project: CRM 프로그램 만들기 (6) | 2025.08.13 |
| 공부 일지 #18 | 이틀치 SQL 따라잡기: DDL, DML, TCL, INDEX, VIEW (4) | 2025.08.08 |
| 공부 일지 #17 | MySQL: Update, Delete, 상관쿼리 → JOIN (3) | 2025.08.08 |
