학습 날짜:2025.08.18
자유도(df, Degree of Freedom)
- 정의: 평균으로부터 자유로운 수
- 보통 n - 1
- 이유: n개의 값 중 마지막 값은 평균으로부터 이미 결정되기 때문에 자유롭지 않음
공식으로 표현
- 자유도(df) = 전체 관측치 수(n) - 제약조건 수
- 평균을 사용했으므로 제약조건 = 1 → df = n - 1
일반적인 활용
- 표본분산(sample variance)
- 분모를 n이 아니라 n-1로 나누는 이유 = 자유도가 n-1이기 때문
(평균을 구하는 데 이미 1개의 자유도가 소모됨)
- 분모를 n이 아니라 n-1로 나누는 이유 = 자유도가 n-1이기 때문
- 검정(test)
- t-test, F-test, χ²-test 등에서 통계량의 분포는 자유도(df)에 따라 달라짐
- 예: t-분포 → df = n-1, χ²-분포 → df = (관측 cell 개수) - 제약조건 수
👉 분포마다 검정 방법이 다르고, 자유도 또한 달라진다.
분포(Distribution)
- 데이터의 "크다/작다"를 판단할 수 있는 기준 제공
- 모분포의 성질을 이해하고, 검정에 활용
주요 분포 종류
- 베르누이 분포 (Bernoulli Distribution)
: 한 번의 시행에서 성공/실패(0 또는 1) 두 가지 결과만 가지는 분포
→ 예: 동전 앞면(1)·뒷면(0) - 이항 분포 (Binomial Distribution)
: 독립적인 베르누이 시행을 n번 반복했을 때 성공 횟수를 따르는 분포
→ 예: 10번 동전 던져 앞면이 나오는 횟수 - 포아송 분포 (Poisson Distribution)
: 단위 시간·공간에서 발생하는 사건의 발생 횟수를 따르는 분포
→ 예: 한 시간 동안 콜센터에 걸려오는 전화 수 - 지수 분포 (Exponential Distribution)
: 포아송 과정에서 사건이 발생할 때까지 걸리는 시간을 따르는 분포
→ 예: 다음 전화가 걸려올 때까지의 대기시간 - 정규 분포 (Normal Distribution)
: 가장 대표적인 연속형 분포, 평균을 중심으로 대칭적 종모양
→ 예: 키, 몸무게, 시험 점수 등 자연·사회 현상에서 자주 등장 - t-분포 (Student’s t-Distribution)
: 표본 크기가 작을 때 평균을 추론하기 위해 사용하는 분포
: 표본 크기가 커질수록 정규분포에 가까워짐
→ 정규분포와 유사하게 좌우 대칭의 종모양, 평균 0 중심, 꼬리가 두꺼움 - χ²(카이제곱) 분포 (Chi-Square Distribution)
: 정규분포 변수를 제곱해 더한 값의 분포(분포의 분포)
: 분산 검정, 독립성 검정 등에 사용
→ 예: 교차표 독립성 검정 - F-분포 (F Distribution)
: 두 개의 χ² 분포를 자유도로 나누어 얻은 비율의 분포
: 주로 분산 비교, ANOVA(분산분석), 회귀분석에 활용
기초통계량 (Descriptive Statistics)
- 기초통계량을 통해 EDA(탐색적 데이터 분석) 가능
- 정의
- 기초통계: 자료를 정리하고 요약하여 특성을 기술하는 기법
- 통계량: 모집단의 모수를 추정하기 위해 표본에서 계산된 값 (평균, 중앙값, 분산, 표준편차, 왜도, 첨도 등)
통계량 구분
- 숫자형 변수
- 위치통계량: 평균, 중앙값, 최빈값, 절사평균, 분위수
- 변이통계량: 범위, 분산, 표준편차, IQR
- 모형통계량: 왜도, 첨도
- 범주형 변수
- 빈도, 상대빈도
위치통계량
- 평균(Mean): 대표적인 자료 중심 척도
- 산술평균(Arithmetic Mean) → 단순 중심값 (예: 시험 점수 평균)
- 기하평균(Geometric Mean) → 비율·성장률 데이터에 적합 (예: 경제 성장률, 투자 수익률)
- 조화평균(Harmonic Mean) → 속도·율, 비율 데이터에 적합 (예: 평균 속도, ML 성능 평가–F1 Score)
- 가중평균(Weighted Mean) → 데이터 중요도 반영 (예: 학점, 시계열 데이터의 가중치 적용)
- 중앙값(Median): 정렬된 데이터의 가운데 값
- 최빈값(Mode): 가장 자주 나타나는 값, 이상치 영향 없음
- 절사평균(Trimmed Mean): 양쪽 극단값을 일정 비율 제외하고 계산한 평균
- 사분위수(Quartile): 데이터를 4등분하는 기준(Q1, Q2=중앙값, Q3). Box plot으로 시각화 가능
변이통계량
- 분산(Variance): 데이터 흩어짐 정도
- 표준편차(Standard Deviation): 분산의 제곱근, 분산은 제곱 단위이므로 표준편차는 원래 단위를 복원, 불규칙성을 측정
- 변동계수(CV): 집단 간 상대적 변동 비교 시 사용
- IQR(Interquartile Range): Q3 - Q1, 중간 50% 데이터 범위로 변동성 판단
모형통계량
- 왜도(Skewness): 분포의 비대칭 정도(왼쪽/오른쪽 치우침)
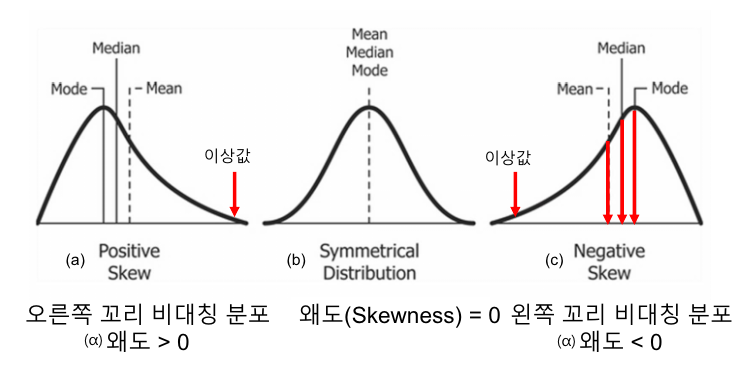
- 첨도(Kurtosis): 분포의 뾰족한 정도, 평균 근처 데이터 집중도

변수의 타입과 시각화 방법
❓ 시각화는 데이터 정리의 한 형태이며, 통계량을 바탕으로 만들어짐
| 수치형 | 범주형 | ||
| 기술(기초) 통계 | 분포분석 - 데이터 특성: 평균, 분산, 표준편차 등 |
빈도분석 - 데이터 특성: 빈도, 비율, 상대도수 |
|
| 시각화 | 일변량 | 히스토그램, box plot | pie chart, bar chart |
| 다변량 | 범주형-수치형: boxplot, bar chart 수치형-수치형: scatter plot |
||
✅ 시계열 데이터는 line chart 이용
'LG U+ Why Not SW Camp 8기 > 학습 로그' 카테고리의 다른 글
| 공부 일지 #24 | Python_Visualization 연습: Matplotlib & Pandas (4) | 2025.08.19 |
|---|---|
| 공부 일지 #23 | Python Pandas 데이터 분석 기초 함수 (0) | 2025.08.19 |
| 공부 일지 #21 | Python Pandas 기본 문법 정리: 데이터 전처리 기초 (8) | 2025.08.14 |
| 공부 일지 #20 | 데이터 분석 기초 정리1: 표본·표집·확률·확률변수 (7) | 2025.08.14 |
| 공부 일지 #19 | SQL Toy project: CRM 프로그램 만들기 (6) | 2025.08.13 |
