학습 날짜: 2025.08.18 ~ 2025.08.19
select_dtypes
원하는 자료형(dtype)의 열만 선택해 추출하는 함수
# 로드한 데이터의 information 확인
df.info()
# int형 변수만 선택
df.select_dtypes(include=['int'])
# int형을 제외한 변수만 선택
df.select_dtypes(exclude=['int'])
# category type 변수의 데이터 기술
df.select_dtypes(include='category').describe()
🔷 자료 type 변환 방법
# type 변환방법
conv_type = { "season": "category",
"holiday":"category",
"workingday":"category",
"weather": "category"}
df = df.astype(conv_type)
df.info()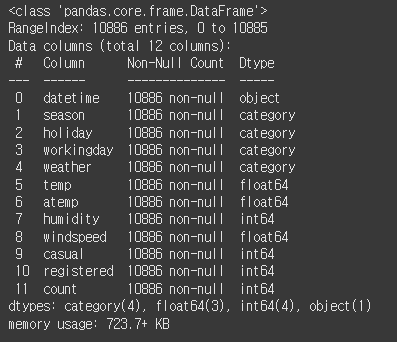
filter
- 행 혹은 열에 대해 index를 사용하여 필터링이 가능함
- 행과 열을 선택하는 방법은 행:axis=0, 열:axis=1
# Filtering을 테스트 하기 위해 datetime 변수를 index로 변경
df_filter.set_index(keys='datetime', inplace = True)
df_filter.head()
# index가 "00:00:00"을 포함하는 행을 Filtering / like 사용
df_filter.filter(like = "00:00:00", axis = 0)
# item option을 사용해서, 원하는 변수만 가져오기
cols = ["humidity", "windspeed"]
df_filter.filter(items = cols, axis = 1) # items는 like랑 같이 못 씀
# 아래와 같이 응용도 가능
df_filter.filter(items = cols, axis = 1).filter(like = "00:00:00", axis = 0)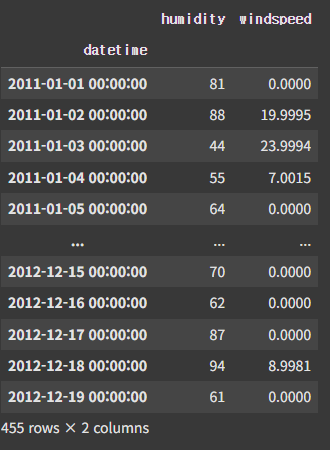
df_filter.filter(items = cols, axis = 1).filter(like = "00:00:00", axis = 0)
출력값
rename
행 또는 열 이름 변경 시 사용하는 함수
# rename을 사용한 행, 열 이름 변경
df_rename.rename(
columns = {"registered": "registered_user",
"casual":"unregistered_user"},
inplace = True
)데이터분석의 기초가 되는 메서드
데이터 가져오기
df = pd.read_csv(path, encoding="utf-8")
# 한글이 변수값으로 설정되어 있는 경우
# encoding 옵션에 "cp949"나 "ecu-kr" 등으로 해야 함데이터 파악하기
# 결측값, 데이터타입, 총 데이터행, 열의 개수, 메모리 사용량 파악해보기
df.info()기초통계량 알아보기
# 변수들의 기초통계량을 파악해보기(숫자형 데이터)
df.describe()
# 변수들의 기초통계량을 파악해보기(문자형(범주형) 데이터), top:최빈값, freq:최빈값의 최대빈도수
df.describe(include = "object")
# or
df.describe(include = "O")
고유값과 빈도수 확인하기
# 범주형 변수에 대한 고유값(범주들)에 대한 빈도수(데이터행의 개수, 카운트)를 나타내 보기
# gender 변수의 고유값과 각 고유값의 빈도수 구해보기
df["gender"].value_counts()
df['age_of_driver'].value_counts() # 연속형 변수에도 가능하나, 보통 사용할 일이 없음
# 특정 변수의 고유값만 나타내 보기
df["gender"].unique()결측값 처리_심화
결측값이 있는 변수와 개수 알아보기
# 변수별 결측값 개수 알아보기
df_miss.isna().sum()
# 결측값이 존재하는 변수(보험청구금액(claim_est_payout))의 행 인덱스 구해보기
cond = df_miss.loc[:, "claim_est_payout"].isna()
df_miss.loc[cond,].index # 결측값인 행 인덱스 추출
df_miss.loc[~ cond,].index # 결측값이 아닌 행 인덱스 추출, ~: 틸다, not을 의미결측값을 평균값으로 대체하기
# 보험청구금액(claim_est_payout)의 결측값들을 평균값으로 대체하기
col = ["claim_est_payout"]
avg_claim_est_payout = df_miss["claim_est_payout"].mean() # NaN을 제외하고 평균값 계산됨
# ───────────────────────────────────────────────
# ver0 : 권장되지 않음 (FutureWarning 발생 가능)
# df_miss[col].fillna(value=avg_claim_est_payout, inplace=True)
# ver1 : 딕셔너리 방식 (가장 많이 쓰임)
nan_replace_data = {"claim_est_payout": avg_claim_est_payout}
df_miss.fillna(value=nan_replace_data, inplace=True)
# ver2 : DataFrame.mean() → Series 반환 → dict 변환 후 사용
# avg_claim_est_payout = df_miss.loc[:, col].mean().to_dict()
# nan_replace_data = {"claim_est_payout": avg_claim_est_payout.get("claim_est_payout")}
# df_miss.fillna(value=nan_replace_data, inplace=True)
# ver3 : 열 단위로 직접 재할당 (간단하지만 덮어쓰기 주의)
# df_miss[col] = df_miss[col].fillna(value=avg_claim_est_payout)
# ───────────────────────────────────────────────
# 차이 이해하기
print(type(df_miss["claim_est_payout"].mean()))
# float (scalar 값) → ver1에서 바로 사용 가능
col = ["claim_est_payout"]
print(type(df_miss.loc[:, col]))
# DataFrame (열 하나라도 DF 형태로 반환됨)
print(type(df_miss.loc[:, col].mean()))
# Series (index=컬럼명, 값=평균) → ver2처럼 dict 접근 필요
# ───────────────────────────────────────────────
# ∴ fillna 문법 정리
# fillna(value, inplace=True)
# → value는 {column명 : 채워넣을 값(scalar)} 형태의 dict 가능
df_miss.isna().sum()ffill / bfill 사용하기
- ffill: 결측값을 앞쪽(이전 행)의 값으로 채우는 방법
- bfill: 결측값을 뒤쪽(다음 행)의 값으로 채우는 방법
# 결측값을 결측값 이전행의 값 또는 이후행의 값으로 대체해보기(fillna)
# method option에 ffill, bfill 이용
# ffill : front fill, bfill : back fill
# witness_present_ind 변수(목격자여부)의 결측값을 fillna를 사용해서 대체해 보자
col = ["witness_present_ind"]
df_miss["witness_present_ind"].fillna(method = "ffill", inplace = True)
# or
# df_miss[col] = df_miss[col].ffill()
df_miss.isna().sum()query 메서드
- query 메서드는 필터링할 조건을 문자열 형태의 인자로 전달하는 방법
- 여러 가지 조건을 and나 or로 동시에 적용할 수 있음
단일 조건의 경우
# 운전자연령(age_of_driver)가 60세 이상만 필터링 해보기
# loc 활용
# cond = (df_query['age_of_driver'] >= 60)
# df_query.loc[cond]
# or (query 사용)
df_query.query("age_of_driver >= 60")다중 조건의 경우
# 다중조건문을 이용한 쿼리
# 운전자연령(age_of_driver)가 60세 이상이고, 성별(gender)가 "M"인 행만 필터링 해보기
df_query.query("age_of_driver >= 60 and gender == 'M'")외부변수를 이용해 조건값 설정하기
# 위의 조건문을 외부변수를 이용해서 조건값을 설정하는 방식으로 수정해보기
target_age = 60
target_gender = "M"
# df_query.query(f"age_of_driver >= {target_age} and gender == '{target_gender}'") # 이것도 가능
df_query.query("age_of_driver >= @target_age and gender == @target_gender") # @가 외부변수 이용하게 해줌문자열 관련 method 사용하기
# 특정문자열값을 통해 데이터를 필터링 하는 경우, 문자열 관련 여러 메서드를 활용할 수 있다.
# 거주형태(living_status)의 값에서 'en'을 포함하는 행만 필터링 하기
df_query['living_status'].value_counts()
df_query.query("living_status.str.contains('en')")
df_query.query("living_status.str.contains('en')")['living_status'].value_counts()
# ───────────────────────────────────────────────
# 거주형태(living_status)의 값에서 'n'으로 끝나는 값을 가진 행만 필터링 하기
# 문자열 조건식, 리스트 포함 여부(in), 사용자 정의 함수가 들어간 조건이라면 engine="python"을 써야 함.
# 현재는 없어도 오류가 안나는 경우가 많지만, engine="python"을 써주면 더 안전하고 가독성 확보
df_query.query("living_status.str.endswith('n')", engine="python")
# ───────────────────────────────────────────────
# isin()을 이용해서, 특정변수에서 특정값을 포함한 행만 필터링 하기
# channel 변수에서 "Broker" 값을 가지는 행만 필터링 하기
df_query["channel"].value_counts()
target_value = ["Broker"]
df_query.query("channel.isin(@target_value)", engine="python")groupby_심화
단일 그룹에 대하여
# 성별(sex)에 대한 생존율을 비교해보자. (생존여부 : survived(0:사망, 1:생존)) - 결과 74% vs 19%
df.groupby("sex")["survived"].mean()
# or
df.groupby("sex").agg({"survived": "mean"})다중 그룹에 대하여
# 다중그룹으로 묶어서 생존율(survived)을 비교해보자.
# 다중그룹(sex, class),
cols = ["sex", "class"]
df.groupby(cols, observed=True)["survived"].mean()다중 그룹 및 다중 집계
# 멀티변수에 대한 분석이 필요한 경우
# 각 그룹별(sex, class) 생존율(survived, 평균)과 연령(age) 최대값을 알아 보자.
# 생존율과 연령에 대해
group_cols = ["sex", "class"]
target_cols = ["survived", "age"]
df.groupby(group_cols)[target_cols].agg({"survived":["mean"], "age":["max"]})
# ↳ 멀티 인덱스로 나옴. ex. age max / [target_cols] 없어도 같은 결과가 나오긴 함
'LG U+ Why Not SW Camp 8기 > 학습 로그' 카테고리의 다른 글
| 공부 일지 #25 | 추론과 검정 정리: 추정, 가설검정, t-test, ANOVA, 카이제곱 (4) | 2025.08.24 |
|---|---|
| 공부 일지 #24 | Python_Visualization 연습: Matplotlib & Pandas (4) | 2025.08.19 |
| 공부 일지 #22 | 데이터 분석 기초 정리2: 자유도, 분포, 기초통계량 (3) | 2025.08.18 |
| 공부 일지 #21 | Python Pandas 기본 문법 정리: 데이터 전처리 기초 (8) | 2025.08.14 |
| 공부 일지 #20 | 데이터 분석 기초 정리1: 표본·표집·확률·확률변수 (7) | 2025.08.14 |
