학습 날짜: 2025.08.20 ~ 2025.08.21
이번에는 추론(Inference)과 검정(Test)에 대해 학습했다. 예전에 심리통계에서 다뤘던 추정(Estimation)과 가설검정(Hypothesis Testing)을 다시 복습할 수 있어 반가웠다. 이번 글에서는 수업 내용을 중심으로, 내가 알고 있던 개념들과 실습 코드를 함께 정리하고자 한다.
중심극한정리; CLT(central limit theorem)
특정 분포를 가정하지 않더라도, 평균(µ)과 표준편차(σ)를 가진 독립적이고 동일한 분포를 따르는 확률표본(iid random variables) 에서 표본의 크기 n이 충분히 커지면, 표본평균 x̄ 의 분포는 정규분포에 수렴한다.
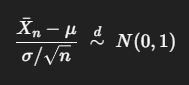
* 추정과 검정의 이론적 토대가 된다.
* n의 크기에 의존한다. ( 보통 n ≥ 30이면 실용적으로 충분)
추정(Estimation)
통계적 원칙에 입각하여 표본으로부터 모수의 값을 추론하는 것 혹은 그 과정
점 추정
표본에서 계산한 통계치(예: x̄, s² )를 이용해 모집단의 모수치(예: μ, σ² )를 추정하는 방법.
- 예: 표본평균 x̄ → 모집단 평균 μ 추정
- 예: 표본분산 s² → 모집단 분산 σ² 추정
1. 점 추정을 하는 이유
- 모수치는 알 수 없기 때문에 직접적으로 “같다”라고 말할 수 없다.
- 따라서 점추정을 통해 표본으로부터 모수의 값을 하나의 수치로 근사한다.
- 추정 방법으로는 불편 추정량(Unbiasedness), 효율성(Efficiency), Consistency(일치성), 최소 제곱 추정법(LSE), 최대 가능도 추정법(MLE)
2. 추정량을 평가하는 기준 (Criteria for Evaluating Estimators)
추정량을 비교하거나 평가할 때 사용하는 대표적인 기준은 다음과 같다.
- 불편성(Unbiasedness)
- 추정량의 기댓값이 모수와 일치하는 성질
- 예: x̄ 는 μ의 불편 추정량.
- 효율성(Efficiency)
- 여러 불편 추정량 중에서, 분산이 가장 작은 추정량을 더 효율적(efficient)이라고 함.
- 일치성(Consistency)
- 표본 크기 n→일 때, 추정량이 모수에 수렴하는 성질.
3. 추정 방법 (Estimation Methods)
추정량을 구하는 대표적인 방법에는 다음이 있다.
- 최소제곱법(Least Squares Estimation, LSE)
- 오차 제곱합을 최소화하는 방식으로 모수를 추정.
- 주로 회귀분석에서 사용.
- 최대가능도추정법(Maximum Likelihood Estimation, MLE)
- 관측된 표본이 나올 확률(가능도, likelihood)을 최대화하는 모수를 선택.
- 일반적으로 가장 널리 쓰이는 추정 방법.
구간 추정
모수(parameter)의 값을 추정할 때, 하나의 값(point)이 아니라 범위(interval)로 추정하는 방법
- 구간추정량(Interval Estimator)
- 두 개의 확률변수(Lower/Upper Bounds)로 이루어진 집합
- 이 구간이 모수를 포함할 확률을 신뢰수준(Confidence Level)이라고 할 수 있다.
- 구간추정값(Interval Estimate): 실제 데이터로 계산된 구간 값
신뢰구간; CI(confidence interval)
실제 표본 데이터를 대입했을 때, 구간추정량이 산출하는 구체적인 구간 값.
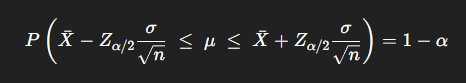
모분산 σ² 을 알고, 표본평균 x̄ 가 정규분포를 따를 때의 신뢰구간은 위와 같다.
- 신뢰수준(Confidence Level):
- 보통 95% 또는 99%를 사용
- 해석: 무한히 표본을 반복 추출해 구간을 계산할 때, 그 중 (1−α)×100%의 구간이 모수를 포함한다.
- ❌ “이 구간이 μ를 포함할 확률이 95%다”는 해석은 틀림 (μ는 고정된 상수).
가설 검정(Hypothesis Testing)
가설 검정(Hypothesis Testing)은 연구 결과가 특정 이론이나 주장을 지지하는지 여부를 판단하는 절차이다.
즉, 표본 데이터를 바탕으로 모집단의 모수(parameter)에 대해 세운 연구자의 가설을 평가하는 방법이다.
⭐추정(Estimation)은 모수의 값을 알아내는 과정이고, 가설 검정(Hypothesis Testing)은 모수에 대한 특정 주장의 진위를 평가하는 절차이다.
가설의 개념
- 가설(Hypothesis): 모집단의 특성에 대해 세운 주장 또는 진술.
- 영가설(Null Hypothesis, H₀): 모집단에서 차이, 효과, 관련성이 존재하지 않는다는 진술. (예: “평균 차이는 없다”)
- 대립가설(Alternative Hypothesis, H₁): 연구자가 실제로 관심을 두고 검증하고자 하는 주장. (예: “평균 차이가 있다”)
- 두 가설은 상호배타적(mutually exclusive, 둘 다 참일 수 없음)이고 포괄적(exhaustive, 효과에 대한 모든 가능한 상황을 포함)이다.
⚠️ 주의: 영가설을 기각한다고 해서 대립가설이 “참”임을 증명하는 것은 아니다. 영가설을 기각한다는 것은 단지, 표본 자료가 영가설 하에서는 관찰되기 어렵다는 근거를 제시하는 것일 뿐이다.
유의수준(Significance Level, α)
- 데이터를 수집하기 전에 연구자가 미리 정하는 값.
- 영가설이 참일 때, 이를 잘못 기각할 확률(제1종 오류, Type I error)에 해당한다.
- 보통 0.05(5%) 또는 0.01(1%)을 사용
검정 통계량(Test Statistic)
- 가설 검정을 위해 표본으로부터 계산되는 값
- 사용되는 검정 방법에 따라 달라짐
- t-test → t값
- ANOVA → F값
- Z-test → Z값
기각역(Rejection Region)
- 영가설이 기각되는 값들의 범위.
- 검정 통계량이 이 영역에 들어가면 영가설을 기각한다.
- 기각역의 경계는 유의수준 α에 따라 결정된다.
모수 검정 vs 비모수 검정
1. 모수(Parametric) 검정
- 모수(Parameters): 모집단의 특성을 나타내는 값(예: 평균 μ, 분산 σ²).
- 모집단의 확률 분포를 가정하고, 표본 데이터(등간척도·비율척도)를 통해 모수를 추론
- 예) 두 집단의 평균이 같은지 확인할 때 사용
- 대표적인 방법: t-test, ANOVA, 회귀분석
모수적 통계방법의 주요 가정
- 정규성(Normality): 모집단이 정규분포를 따른다.
- 검정 방법: Shapiro-Wilk, Kolmogorov-Smirnov, Q-Q Plot, 히스토그램
- 등분산성(Homogeneity of Variance): 집단 간 분산이 동일하다.
- 척도의 수준: 표본 데이터가 최소한 등간척도나 비율척도여야 한다.
2. 비모수(Non-Parametric) 검정
- 모집단이 특정 분포를 따른다고 가정할 수 없을 때 사용.
- 데이터가 명목척도나 서열척도로 측정된 경우에 사용.
- 따라서, 평균이 아닌 중앙값이나 순위를 비교하며, 관측값들의 순위(rank) 또는 부호(sign)를 활용한다.
- 예) 두 집단의 중앙값이 같은지 확인할 때
- 대표적인 방법: Chi-square(카이제곱), McNemar, Cochran 검정 등
T-Test
두 집단 이하의 평균 차이를 검정하는 방법
모수 검정에 속하므로 정규성과 등분산성이 충족되어야 하며, 데이터는 등간척도 또는 비율척도여야 한다.
단측검정 vs 양측검정
- 단측검정(One-sided test): 평균이 특정 값보다 크거나 작은지를 검정할 때 사용.
- 양측검정(Two-sided test): 평균이 특정 값과 “같지 않음”을 검정할 때 사용.
- 양측검정의 경우, 유의수준 α를 양쪽으로 나누어, 각 꼬리 부분이 α/2가 됨.
- 예: α = 0.05라면, 양쪽 끝에 각각 0.025씩 분포.
t-test의 종류
- One-sample t-test (단일 표본 t-검정)
- 모집단 평균이 사전에 가정된 값(μ₀)과 같은지 검정.
- 예: 한 집단의 평균 점수가 100점과 동일한지 확인.
# one sample t-test: ttest_1samp(dv, H0)
# H0: df["weight"] == 15(귀무가설 기댓값)
# H1: df["weight"] != 15
E_HO = 15
stats.ttest_1samp(df["weight"], E_HO)- Two-sample t-test (독립 표본 t-검정)
- 서로 독립적인 두 집단 간 평균 차이를 검정.
- 예: 남녀 두 집단의 시험 점수 차이 비교.
'''
등분산 검정 ==> statistic : F-value
등분산 검정을 수행하는 함수가 array type의 parameter를 가지기 때문에 array로 변환 후 검정
'''
stats.bartlett(np_arr_prom_y, np_arr_prom_n) # array
'''
등분산 검정 결과에 따라 독립표본 t-검정 실행
two-sample t-test: ttest_ind(a_dv, b_dv, equal_var = T/F)
eqaul_var : True(분산이 같을 때), False(분산이 틀릴 때)
'''
stats.ttest_ind(np_arr_prom_y, np_arr_prom_n, equal_var=True)- Paired t-test (대응 표본 t-검정)
- 동일한 대상의 전후 차이나 쌍으로 묶인 데이터의 평균 차이를 검정.
- 두 집단의 표본 크기가 동일해야 함
- 예: 약물 투여 전후의 혈압 차이, 교육 전후 성취도 변화.
# paired t-test: ttest_rel(x_dv, y_dv)
# 대응표본 t-검정 (series 값을 넣으면 오류가 날수도 있으니 array 바꾸기)
stats.ttest_rel(y_df['sales_amt'].values, n_df['sales_amt'].values)ANOVA
- 2개 이상의 집단 간 평균을 비교하기 위한 검정
- 독립변수(IV): 범주형 변수, 종속변수(DV): 연속형 변수
- 대표 검정통계량: F값
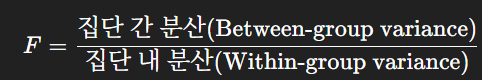
- 주요 개념
- 요인(Factor): 독립변수(범주형 변수)
- 수준(Level): 한 요인이 가지는 각 범주 값 (2개 이상)
가정(Assumptions)
- 정규성(Normality): 모집단이 정규분포를 따르는 성질
- 등분산성(Homogeneity of variance): 집단 간 분산이 동일한 성질
- 독립성(Independence): 각 집단의 표본이 서로 독립적인 성질
분산분석의 논리
- 평균 차이만 보는 것이 아니라, 두 가지 변산(변동)을 함께 고려한다.
- 집단 간 변산: 집단 평균 간 차이 정도
- 집단 내 변산: 같은 집단 내 점수들의 흩어진 정도
- 판단 기준
- 집단 간 변산 > 집단 내 변산 → 집단 차이 유의 ( 유의할 가능성 ↑ )
- 집단 간 변산 < 집단 내 변산 → 집단 차이 유의하지 않음
가설
- 영가설(H₀): 모든 집단 평균은 같다
- 대립가설(H₁): 적어도 한 집단 평균은 차이가 있다
- 유의한 차이가 있을 경우, 사후분석(Post-hoc test)으로 어떤 집단 간 차이가 존재하는지 확인해야 한다.
ANOVA 종류
- 일원 독립 ANOVA (One-way Independent ANOVA)
- 집단 간 설계(Between-subjects design)
- 서로 다른 집단 간 평균 비교
# 연령대별 SNS 사용시간이 등분산인지 검정하기 위해 Bartlett's test 를 수행
grp = df["age_grp"].unique()
cond1 = (df["age_grp"] == grp[0])
cond2 = (df["age_grp"] == grp[1])
cond3 = (df["age_grp"] == grp[2])
cond4 = (df["age_grp"] == grp[3])
cond5 = (df["age_grp"] == grp[4])
cond6 = (df["age_grp"] == grp[5])
sp.stats.bartlett(
df.loc[cond1, "use_time" ].values,
df.loc[cond2, "use_time" ].values,
df.loc[cond3, "use_time" ].values,
df.loc[cond4, "use_time" ].values,
df.loc[cond5, "use_time" ].values,
df.loc[cond6, "use_time" ].values,
)
'''
BartlettResult(statistic=np.float64(9.831118547662085), pvalue=np.float64(0.0801643178333404))
여기서의 귀무가설(H₀)은 ‘모든 집단의 분산이 동일하다’이다.
검정 결과 p-value가 0.05보다 크므로 귀무가설을 기각할 수 없으며,
따라서 집단 간 분산은 동일하다고 볼 수 있다.
'''
# pingouin 패키지 사용
# 등분산: pg.anova(), 이분산: pg.welch_anova()
pg.anova(data = df, dv="use_time", between="age_grp")
# 사후분석
from statsmodels.stats.multicomp import MultiComparison
mc = MultiComparison(data = df['use_time'], groups = df["age_grp"])
print(mc.tukeyhsd())- 반복측정 ANOVA (Repeated Measures ANOVA, RM-ANOVA)
- 집단 내 설계(Within-subjects design)
- 동일한 대상이 여러 조건에서 반복 측정된 경우 평균 비교
- 혼합형 ANOVA (Mixed ANOVA)
- 집단 간 요인 + 집단 내 요인을 동시에 고려
- 일부 요인은 between, 일부 요인은 within
사후 검증의 종류
- 분산분석 결과가 유의하고, 요인의 수준(Level)이 3개 이상일 때 실시한다.
- 수준이 2개뿐인 경우라면, 유의하다는 것은 이미 두 집단 간 차이가 있음을 의미하므로 별도의 사후검정이 필요하지 않다.
- 사후검정의 종류는 1종 오류(Type I error)를 얼마나 잘 통제하는가에 따라 구분된다.

Chi-squre (카이제곱 검정)
- 카이제곱 분포(χ² distribution)에 기초한 비모수적 검정 방법
- 관측된 도수(observed frequency)가 기대도수(expected frequency)와 통계적으로 유의미하게 다른지를 검정
- 주로 범주형 자료(categorical data) 분석에 사용
검정 절차
1. 분할표 작성: 범주형 변수의 교차 빈도표 작성
2. 기대도수 도출: 귀무가설 하에서 기대되는 빈도 계산
3. 카이제곱 통계량 산출
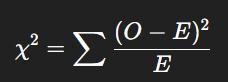
- OO: 관측도수(Observed frequency)
- EE: 기대도수(Expected frequency)
4. 검정: 자유도(df)와 유의수준(α)에 따른 χ² 분포의 임계값(critical value)과 비교하여, 귀무가설 기각 여부를 판
카이제곱 검정의 종류
- 적합도 검정 (Goodness-of-fit test)
- 모집단이 특정 분포를 따른다고 가정할 수 있는지 검증
- 예: “사과 색깔 분포가 빨강:초록:노랑 = 2:3:5인지 확인”
# 1. 관측도수 산출
X = pd.crosstab(serious_df['sex'], serious_df['age'], margins=True) # margins=True : 빈도 합계를 구해줌
m = X.values[1, :5]
# 기존에 알려진 '남성의 심각한사고의 비율'
# 10%, 20%, 20%, 30%, 20%
pr = np.array([0.1, 0.2, 0.2, 0.3, 0.2])
pr.sum() # 1이 되어야 함
# 2. 기대도수 산출
E = m.sum() * pr
m.sum(), E.sum() # 두 값이 같아야 함
# 3. 카이제곱 검정 : chisquare(관측도수, 기대도수)
stats.chisquare(f_obs=m, f_exp=E)- 독립성 검정 (Test of independence)
- 두 범주형 변수 간 관련성 여부 검정
- 예: 혈액형과 성격 유형 간의 관계, 성별과 브랜드 선호 간의 관계
'''
1. 성별, 심각한사고여부, 범주형 독립변수에 대해 빈도교차표 구성
'''
X = pd.crosstab(df['sex'], df['serious_yn'], margins=True)
m = X.values[:2, :2]
# or
# m = X.loc[["M", "F"], ["N", "Y"]]
'''
2. 카이제곱 검정
chi2_contingency(빈도교차표의 값)
'''
stats.chi2_contingency(m)
'''
결과 값 : 검정통계량_카이제곱통계량, 유의확률(p-value), 자유도, 각 셀의 기대도수
Chi2ContingencyResult(statistic=np.float64(3.7895026717172966),
pvalue=np.float64(0.051574970410524265),
dof=1,
expected_freq=array([[286.99343955, 30.00656045], [679.00656045, 70.99343955]]))
'''- 동질성 검정 (Test of homogeneity)
- 서로 다른 모집단에서 범주형 자료의 분포가 동일한지 검정
- 예: 지역별 고객 집단이 같은 브랜드 선호 분포를 보이는지 확인
'LG U+ Why Not SW Camp 8기 > 학습 로그' 카테고리의 다른 글
| 공부 일지 #27 | 통계 및 실습: 회귀(복습), 로지스틱회귀 (1) | 2025.09.02 |
|---|---|
| 공부 일지 #26 | 통계 및 실습: 상관, 회귀 (4) | 2025.08.26 |
| 공부 일지 #24 | Python_Visualization 연습: Matplotlib & Pandas (4) | 2025.08.19 |
| 공부 일지 #23 | Python Pandas 데이터 분석 기초 함수 (0) | 2025.08.19 |
| 공부 일지 #22 | 데이터 분석 기초 정리2: 자유도, 분포, 기초통계량 (3) | 2025.08.18 |
