학습 날짜: 2025.09.02
회귀 분석(복습)
1. 회귀모델과 목표
- 데이터는 학습 데이터 / 테스트 데이터로 나누어 사용
- 예측값과 실제값의 차이를 최소화하는 것이 목표
- yi - ŷi= 0 (오차 최소화)
- MSE(Mean Squared Error):

- MSE ≈ 0 이 되도록 최적화된 β(계수) 값을 찾음
- MSE 같은 함수를 목표함수 / 비용함수 (cost function) 라고 부름
2. 회귀의 종류
- 단순 선형 회귀: 하나의 독립변수로 최적의 회귀선 탐색
- 다중 선형 회귀: 여러 독립변수를 결합 → 여전히 선형 형태 유지
- β0 : 여러 회귀선의 오류 조율자(절편 역할)
3. 선형 회귀의 주요 가정
- 선형성: 독립변수와 종속변수의 관계가 선형이어야 함
- 정규성: 오차항이 정규분포를 따름
- 등분산성: 독립변수 값에 따라 오차항의 분산이 일정해야 함
- 독립성: 오차항끼리 서로 독립이어야 함
4. 결정계수 (R², adjusted R²)

- SSR: 독립변수가 설명하는 분산
- SST: 종속변수의 전체 분산
- 주의할 점
- R² 값이 높아도 학습데이터에 대해서만 높을 수 있음 → 과적합 위험
- 모델은 변수의 의미(x의 본질)를 알지 못하고, 단순히 수학적 관계만 학습
- 따라서 R²와 adjusted R²를 함께 확인해야 함
- adjustedR²: 변수 개수를 반영하여 보정된 값
로지스틱 회귀분석
1. 기본 개념
- 종속변수(y)가 범주형(특히 이항, 0 또는 1)일 때 사용하는 분석 방법.
- 분류 분석 모델에 해당하며, X(입력변수)로부터 Y(출력, 범주형)를 예측한다.
- 기준값(보통 0.5)보다 크면 목표집단(1), 작으면 비목표집단(0)으로 분류한다.
2. 시그모이드 함수 (Sigmoid Function)
- 선형 방정식 y = β0 + β1x의 값을 그대로 확률로 볼 수 없으므로, 시그모이드 함수를 통해 확률로 변환한다.
- 시그모이드 함수는 미분이 쉽고, 값의 범위가 0~1이므로 확률 해석이 가능하다.

- 해석:
- β0 : 그래프의 좌우 이동(절편)
- β1: 기울기(독립변수 효과 크기)
3. Odds와 Logit 변환
- 사건이 발생할 확률을 p, 발생하지 않을 확률을 1-p라 할 때:
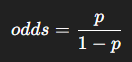
- 오즈는 0 이상 무한대까지의 값을 가진다. 즉, [0, ~∞]
- 오즈에 로그를 취하면, 다시 선형 방정식으로 표현 가능하다 (logit transform).

- 따라서 로지스틱 회귀는 선형 결합을 logit(로그 오즈)으로 연결한 모델이다.
- 수식 전개 참고:

4. 회귀계수 추정: 최대우도추정(MLE)
- 최소제곱법(OLS)이 아닌 최대우도추정법(Maximum Likelihood Estimation, MLE) 사용.
- 우도(Likelihood): 주어진 데이터가 특정 계수값에서 관측될 확률.
- 우도가 클수록 추정된 계수가 데이터와 잘 맞음을 의미한다.
5. 적합도 검정
- 유사결정계수(Pseudo R²) 사용:
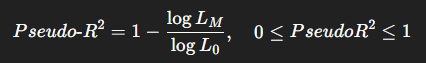
- log L_M: 추정된 모델의 로그 우도
- log L_0: 기초 모델(설명변수 없는 경우)의 로그 우도
- z-통계량을 활용하여 회귀계수의 유의성 검정 수행.
6. 해석
- β1은 log-odds(로그 오즈) 단위로 해석된다.
- 즉, X가 1 증가할 때 log(odds)가 β1만큼 변한다는 뜻.
- log-odds는 직관적으로 이해하기 어렵기 때문에, 지수 변환(exp)을 해서 해석한다.
- exp(β1)을 odds ratio라고 부르며, 이는 독립변수 X가 1 단위 증가할 때 odds가 몇 배로 변하는지를 의미한다.
로지스틱 회귀분석 실습
1. 데이터 설명
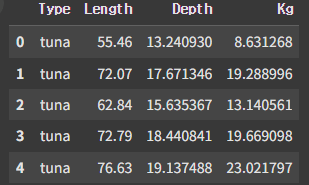
- Type : 생선 종류(tuna, salmon, Mackerel)
- Length: 생선의 가로 방향 길이
- Depth: 생선의 세로 방향 길이
- Kg: 생선 무게
2. 파생변수(Target) 만들기
target 생선은 tuna이다.
# target 변수에 tuna => 1, 다른 고기 종류는 => 0 으로 dummy coding for binary classification
df['Target'] = np.where(df['Type'] == 'tuna', 1, 0)
3. 데이터 시각화
'''
그래프의 재해석 -> scatter plot (산점도)
x와 y축을 모두 독립변수로 두면, 그룹화된 데이터를 확인하여 y를 예측할 수 있음
'''
fig = plt.figure(figsize=(8,5))
ax = fig.gca() # sns 사용하려면 도화지(gca) 만들어야 함
sns.scatterplot(data = df, x = 'Length', y = 'Kg', hue = 'Type', ax = ax)
plt.show()
4. 모델 만들기
# 모델 만들기1
cols = ['Length','Depth', 'Kg']
X = df[cols]
Y = df['Target']
X = sm.add_constant(X) # 상수항 열(beta_0)을 추가
# logistic 회귀분석 모델 만들고 학습
model = sm.Logit(Y, X) # Y먼저!
model = model.fit()
print(model.summary())
'''
Optimization terminated successfully.
Current function value: 0.005386
Iterations 15
Logit Regression Results
==============================================================================
Dep. Variable: Target No. Observations: 2100
Model: Logit Df Residuals: 2096
Method: MLE Df Model: 3
Date: Tue, 02 Sep 2025 Pseudo R-squ.: 0.9915
Time: 05:16:39 Log-Likelihood: -11.310
converged: True LL-Null: -1336.7
Covariance Type: nonrobust LLR p-value: 0.000
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 28.0420 8.786 3.192 0.001 10.821 45.263
Length -1.8097 0.752 -2.406 0.016 -3.284 -0.335
Depth 2.3264 2.018 1.153 0.249 -1.630 6.283
Kg 5.2510 1.395 3.763 0.000 2.516 7.986
==============================================================================
Possibly complete quasi-separation: A fraction 0.93 of observations can be
perfectly predicted. This might indicate that there is complete
quasi-separation. In this case some parameters will not be identified.
coef : 가중치 값이 됨
Depth가 유의하지 않으니 제거
Length + Kg 는 유의함 => 두 개의 변수로 모델 새로 만들기
'''# 모델 만들기2
cols = ['Length', 'Kg']
X = df[cols]
Y = df['Target']
X = sm.add_constant(X) # 상수항 열(beta_0)을 추가
# logistic 회귀분석 모델 만들고 학습
model = sm.Logit(Y, X) # Y먼저!
model = model.fit()
print(model.summary())
'''
Logit Regression Results
==============================================================================
Dep. Variable: Target No. Observations: 2100
Model: Logit Df Residuals: 2097
Method: MLE Df Model: 2
Date: Tue, 02 Sep 2025 Pseudo R-squ.: 0.9910
Time: 05:16:41 Log-Likelihood: -12.056
converged: True LL-Null: -1336.7
Covariance Type: nonrobust LLR p-value: 0.000
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
const 23.4419 6.001 3.906 0.000 11.681 35.203
Length -1.1276 0.271 -4.161 0.000 -1.659 -0.596
Kg 5.0476 1.176 4.293 0.000 2.743 7.352
==============================================================================
Possibly complete quasi-separation: A fraction 0.91 of observations can be
perfectly predicted. This might indicate that there is complete
quasi-separation. In this case some parameters will not be identified.
'''
# 결과해석
'''
length, kg - coef 값 사용
length 1단위 증가할때 -1.1276 오즈비 배수 증가
원래 수로 변화하면, length 1단위 증가할때 0.32배 증가
'''
round(np.exp(-1.1276), 2), round(np.exp(5.0476),2)5. Model Test
'''
# Y 값 = df['Target'] 임
# 학습데이터와 마찬가지로 파생변수 생성
# target 변수에 tuna => 1, 다른 고기 종류는 => 0 으로 dummy coding for binary classification
'''
test_df['Target'] = np.where(test_df['Type'] == 'tuna', 1, 0)
test_df.head()
# 테스트할 일부 데이터 선택
sample_df = test_df.groupby('Target', group_keys = False).apply(lambda x: x.sample(5))
# 테스트 모델 만들기
cols = ['Length', 'Kg']
test_X = sample_df[cols]
test_Y = sample_df['Target']
test_X = sm.add_constant(test_X) # 상수항 열을 추가
test_X
# model prediction
pred_y = model.predict(test_X)
pred_y
# 모델 성능 판단하기
conf_table = model.pred_table() # confusion matrix
conf_table # -> 학습 모델 성능 판단 근거
'''
array([[1397., 3.], -> True Negative, False Negative
[ 3., 697.]]) -> False Positive, True Positive
정확도: (TN + TP)/ 전체
''''LG U+ Why Not SW Camp 8기 > 학습 로그' 카테고리의 다른 글
| 공부 일지 #29 | 머신러닝 경험해보기: KNN 알고리즘 (0) | 2025.09.05 |
|---|---|
| 공부 일지 #28 | 머신러닝 첫걸음: 개념, 유형, 흐름 (1) | 2025.09.03 |
| 공부 일지 #26 | 통계 및 실습: 상관, 회귀 (4) | 2025.08.26 |
| 공부 일지 #25 | 추론과 검정 정리: 추정, 가설검정, t-test, ANOVA, 카이제곱 (4) | 2025.08.24 |
| 공부 일지 #24 | Python_Visualization 연습: Matplotlib & Pandas (4) | 2025.08.19 |
