학습 날짜: 2025.08.25
상관(Correlation)
1. 연관성을 공부하는 이유
- 인과관계(Causality)
- 두 변수 간에 인과성이 있다면 반드시 어떤 형태로든 연관성이 나타난다.
- 그러나 연관성이 있다고 해서 반드시 인과성이 있는 것은 아니다.
- 따라서 연관성은 잠재적 인과관계를 탐색하는 간접적 증거일 뿐이다.
- 즉, "상관 ≠ 인과"라는 점을 항상 유념해야 한다.
- 예측력(Predictability)
- 연관성이 있다는 것은 두 변수가 서로 의존적(Dependent)임을 뜻한다.
- 한 변수의 값이 다른 변수의 분포에 영향을 줄 수 있으며, 이를 통해 예측 가능성이 생긴다.
📌 따라서 변수들 간의 연관성을 수치적으로 측정하고 검정하는 과정이 필요하다. 이때 사용되는 대표적인 방법이 바로 상관분석(Correlation Analysis) 이다.
2. 상관분석(Correlation Analysis)의 목적
- 연관성을 정량화하여 변수 간 관계의 강도와 방향을 파악.
- 추론: 변수 간의 관계를 탐색하고 가설을 세우는 근거 제공.
- 예측: 한 변수를 활용해 다른 변수를 추정할 수 있는 기반 제공.
3. 선형 연관성(Linear Association)
(1) 공분산(Covariance)
- 두 변수가 함께 변하는 정도를 나타내는 지표.
- 상관관계의 방향성만 알 수 있음
- 모집단 공분산:

- 표본 공분산(추정치):

- 해석:
- Cov(X,Y) > 0: 두 변수가 같은 방향으로 변함 (정적 관계)
- Cov(X,Y) < : 두 변수가 반대 방향으로 변함 (부적 관계)
- Cov(X,Y) ≈ 0: 선형적 관계 없음
- 단위 의존성: 변수의 측정 단위에 따라 값이 달라지므로 절대적 크기 해석이 어렵다.
(2) 피어슨 상관계수(Pearson’s r)
- 공분산을 두 변수의 표준편차로 나눈 값 → 단위 제거, 해석 가능.
- 범위: -1 ≤ r ≤ 1
- 특징:
- |r|이 1에 가까울수록 선형 관계가 강하다.
- r = 0 → 선형 상관 없음(단, 비선형 관계 가능성은 있음).
- 표기는 소문자 r(대문자 R 아님).
- 주의: 상관계수의 부호나 기울기만으로 인과성을 주장할 수 없음.
#피어슨 상관계수 출력
cols = ['temperature', 'precipitation', 'supply']
corr_df = df[cols]
corr_df.corr(method = 'pearson') # 검정 결과를 알려주지 않음
# 피어슨 상관계수 검정
stats.pearsonr(df['precipitation'], df['supply'])
'''
출력값
PearsonRResult(
statistic=np.float64(0.029112397696058924),
pvalue=np.float64(0.1679221707005177))
p = 0.17이므로 영가설 채택, 상관성 없음
'''
4. 비선형 연관성(Nonlinear Association)
(1) 스피어만 상관계수(Spearman’s rho)
- 두 변수 값의 순위(Rank)를 구한 뒤, 순위 간 피어슨 상관계수를 계산.
- 단조(monotonic) 관계를 측정 → 선형일 필요 없음.
- 극단값(Outlier)에 덜 민감.
- 주로 서열척도 변수나 분포 가정이 어려운 경우 사용.
(2) 켄달의 타우(Kendall’s tau)
- 관측치 쌍 간 순서가 일치하는지(Concordant), 불일치하는지(Discordant)로 측정.
- 범위: -1 ~ +1
- 스피어만보다 더 보수적이고, 표본 수가 적거나 서열척도 데이터에서 특히 유용.
- 순위 일관성에 더 직접적으로 초점.
5. 비상관(Uncorrelated) vs 독립(Independence)
- 비상관(Uncorrelated): 상관계수가 0 → 선형적 관계가 없음.
- 독립(Independent): 한 변수의 값이 다른 변수에 영향을 주지 않음. 수학적으로 P(A∩B)=P(A)P(B)
- 관계:
- 독립이면 항상 비상관.
- 비상관이라고 해서 독립은 아님.
- 예외: 변수가 모두 정규분포를 따른다면, 비상관 ↔ 독립이 동일해짐.
6. 상관의 패턴과 시각화
- 선형 상관: 산포도에서 점들이 직선에 가깝게 배열.
- 비선형 상관: 곡선이나 다른 체계적 패턴 존재.
- 상관 없음: 뚜렷한 패턴 없음.
📌 분석 전 반드시 산포도 시각화로 관계 확인 필요.
'''
seaborn lib를 이용해서 대각선은 각 feature의 분포를 보여주며,
선형관계가 있는지를 한눈에 파악하실 수 있음.
이때 pairplot을 사용!
pairplot?
- 그리드(grid)형태로 각 집합의 조합에 대해 히스토그램과 분포도(scatter plot)를 그린다.
- 숫자형 column에 대해서만 그려줌
- 변수가 많지 않을 때 사용하는 것을 권장
'''
sns.pairplot(corr_df, kind = "scatter")
plt.show()

7. 상관분석의 종류
- 단순 상관(Simple Correlation): 두 변수 간의 관계. 상관계수(r)에 대해 t-검정 가능.
- 중다 상관(Multiple Correlation): 세 변수 이상 간의 관계.
- 부분 상관(Partial Correlation): 특정 변수를 통제한 상태에서 나머지 변수 간의 관계를 측정.
8. 상관계수 해석
- 상관계수? 두 변수 간의 선형적 관계의 강도
- 수치 범위: -1.00 ~ +1.00
- 절댓값 |r|이 클수록 강한 상관.
- 0은 독립을 의미하지는 않음(단지 선형 관계 없음).
- 실무 기준(경험적):
- 0.1 이상 → 후보군으로 고려.
- 0.2 이상 → 일정한 경향성을 보임.
- 0.6 이상 → 매우 강한 상관.
- 참고 사이트: https://www.jmp.com/ko/statistics-knowledge-portal/what-is-correlation/correlation-coefficient
9. 상관계수의 왜곡 요인
- 제한된 범위(Range Restriction): 표본의 범위가 좁으면 상관이 축소됨.
- 집단 결합(Combined Groups): 결합된 집단의 상관계수는 달라질 수 있음.
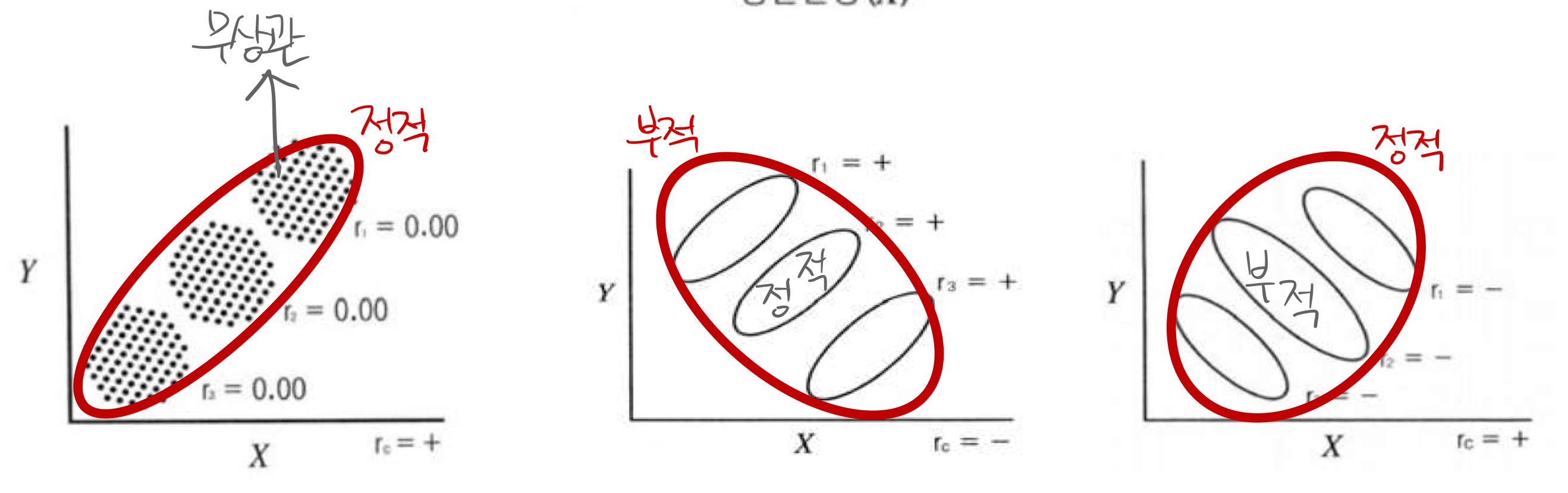
- 극단값(Outliers):
- 회귀선 방향의 극단값 → r을 증가시킴.
- 회귀선에서 벗어난 극단값 → r을 감소시킴.
10. 상관분석 주의점
- 시계열(Time-series) 데이터는 관측치들이 시간에 따라 연속적이고 자기상관을 가지므로, 관측치 간 독립성 가정이 깨져 단순 상관분석에는 적절하지 않음.
- 연관성은 인과성을 의미하지 않음.
회귀
1. 회귀분석의 목적
- 통계학에서의 목적: 독립변수 X와 종속변수 Y 간의 관계 구조를 모형화하고, 인과성 가능성을 탐색.
- 머신러닝에서의 목적: X를 입력하면 예측값 ŷ 을 산출하는 예측 모델 구축.
2. 회귀모델의 개념
- 정의: 독립변수 X의 정보를 이용해 종속변수 Y(연속형)의 값을 설명·예측하는 통계적 방법.
- 상관 분석 vs 회귀분석:
- “마케팅 횟수와 매출이 관련이 있는가?” → 상관분석.
- “마케팅 횟수가 1 증가하면 매출은 평균적으로 얼마나 변하는가?” → 회귀분석.
- 📌 주의: Causality ⇒ Association은 가능하지만, Association ⇒ Causality는 아님.
즉, 상관관계가 곧 인과관계는 아니다.
- 용어:
- Y = 종속변수(Dependent Variable), 반응변수(Response)
- X = 독립변수(Independent Variable), 설명변수(Predictor, Feature, Regressor)
3. 선형 회귀분석
모형:

β: 절편(intercept), X=0일 때 Y의 예측값
: 기울기(slope), X가 1 증가할 때 Y의 평균적 변화량
εi: 오차항(error), 관측되지 않은 확률적 변동
종류:
- 단순 선형 회귀(Simple Linear Regression): 독립변수가 1개
model = smf.ols("CMEDV~RM", data=df)
model = model.fit()
print(model.summary())
- 다중 선형 회귀(Multiple Linear Regression): 독립변수가 2개 이상
# 표준화
# z = (x-min)/std
cols = df.columns[1:]
df[cols] = (df[cols] - np.min(df[cols], axis = 0)) / np.std(df[cols], axis = 0)
Y = df["CMEDV"]
X = df[cols]
X = sm.add_constant(X)
model = sm.OLS(Y, X).fit()
print(model.summary())
- “회귀”라는 이름은 평균으로의 회귀(regression to the mean) 현상에서 유래.
4. 선형 회귀분석의 주요가정
회귀계수의 추론이 타당하려면 잔차(Residuals)에 대해 다음 가정이 필요하다:
선형성(Linearity): X와 Y의 관계가 선형.
# 선형성
df.plot(kind = 'scatter', x = 'RM', y = 'CMEDV')
plt.show()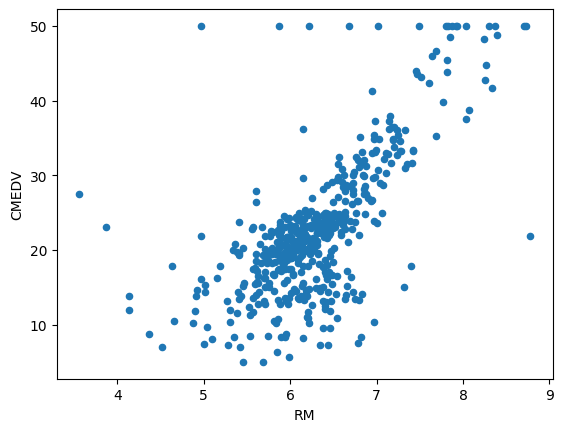
독립성(Independence): 잔차들이 서로 독립.
# 잔차의 독립성
# Durbin-waston 검정 수치(0~4)가 2에 가깝다면, 잔차들이 독립적
model = smf.ols("CMEDV~RM", data=df)
model = model.fit()
print(model.summary())
등분산성(Homoscedasticity): 잔차의 분산이 일정.
# 잔차의 등분산성 => 잔차 산점도
sns.residplot(data = df,
x = "RM",
y = "CMEDV" )
plt.show()
정규성(Normality): 잔차가 평균 0, 분산 인 정규분포 → t/F 검정 근거.
from scipy.stats import probplot
fig = plt.figure(figsize = (8,5))
ax = fig.add_subplot()
probplot(x = model.resid, dist = 'norm', plot = ax)
plt.show()
5. 선형회귀 모델 구축
- 모델 구축 과정 = 모델 선택 + 계수 추정
- 변수 선택 방법:
- 통계적 검정(t/F 검정 등)을 이용해 회귀계수가 유의하지 않은 변수는 제거
- AIC(Akaike Information Criterion) 등 정보 기준 활용 (값이 작을수록 적합도가 좋음)
- 최소제곱 기준: 각 점들과 회귀선 사이의 편차 제곱합이 최소가 되도록 직선을 선택.
- 회귀 방정식 산출: 위 기준을 만족하는 회귀계수(β0, β1)를 결정.
- 예시:
# 유의하지 않는 변수(INDUS, AGE) 제거
cols = ['CRIM', 'ZN', 'CHAS', 'NOX', 'RM', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT']
Y = df["CMEDV"]
X = df[cols]
X = sm.add_constant(X)
model = sm.OLS(Y, X).fit()6. 회귀계수 추정
(1) 최소제곱법 (Least Squares Estimation, LSE)
- 각 점과 회귀선 사이의 편차 제곱합을 최소화하는 직선을 찾음.
- 추정식 (단순회귀):

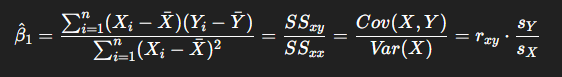
- “최적의 선”이란 모든 점들과의 거리(잔차)를 제곱합으로 정의하고, 그 값을 최소화한 것.
(2) 최대우도법 (Maximum Likelihood Estimation, MLE)
- 잔차가 정규분포를 따른다고 가정하면, LSE와 동일한 추정값을 줌.
- 머신러닝에서는 LSE 손실함수 = MLE 로그우도 최대화 = cost function 최소화와 같은 맥락
7. 회귀모형의 해석
- 예측값:
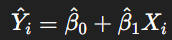
- 절편(β0 hat): X=0일 때의 예측값.
- X=0이 의미 없는 경우 → 해석 가치 낮음.
- X를 중심화(centering)하면, 절편은 “X 평균 수준에서의 Y 예측값”이 됨.
- 기울기(: X가 1 단위 증가할 때 Y의 평균 변화량.
- 0보다 크면 Y 증가, 0보다 작으면 Y 감소.
- 추정치의 표준오차(Standard Error of Estimate, Syx):

8. 분산 분해와 결정계수
총 분산 분해:SST=SSR+SSE
- SST (Total Sum of Squares): 총 분산
- SSR (Regression SS): 회귀선이 설명한 분산
- SSE (Error SS): 설명되지 않은 분산
결정계수:

- Y의 변동성 중 X가 설명하는 비율
- 1에 가까울 수록 추정한 회귀선의 설명력이 높다고 할 수 있음
- 단순회귀에서는 R²
9. 유의성 검정
- 단순회귀에서 기울기 t-검정 ↔ 상관계수 r의 t-검정과 동일.
- 전체 모형 F-검정: 회귀식이 유의미한 설명력을 가지는지 평가.
- 다중회귀: 각 계수에 대한 개별 t-검정, 전체모형 F-검정.
10. 주의사항
- 다중공선성: 다중회귀분석에서 독립변수들 간 상관관계가 높아 회귀계수 추정이 불안정해지는 현상
- 분산팽창계수(VIF, Variance Inflation Factor)란 다중회귀분석에서 특정 독립변수 𝑋𝑗가 다른 독립변수들과 얼마나 상관되어 있는지를 수치로 나타낸 지표로, 일반적으로 VIF > 10이면 심각한 다중공선성으로 판단
# 다중공선성 체크 => VIF(Variance inflation Factor : 분산 팽창 지수)
# VIF : 5~10 -> 다중공선성 발생 가능성 0
# VIF : > 10 -> 다중공선성 발생
from statsmodels.stats.outliers_influence import variance_inflation_factor
X.drop(['const'], inplace = True, axis = 1)
VIF = pd.DataFrame()
VIF['Feature'] = X.columns
VIF["VIF_Factor"] = [ variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
print(VIF)
'''
Feature VIF_Factor
0 CRIM 2.096421
1 ZN 2.769977
2 CHAS 1.137890
3 NOX 10.035857
4 RM 13.712680
5 DIS 7.252158
6 RAD 13.139692
7 TAX 19.581303
8 PTRATIO 12.551330
9 B 15.513754
10 LSTAT 6.874844
RAD, TAX 변수가 조금은 겹쳐있다고 해석할 수 있음
만약 하나가 10을 넘으면 둘 다 같이 넘음
아직 잠재적인 값이므로 굳이 삭제하지 않음
'''- 이상치/영향점: 계수와 회귀선에 큰 영향을 줄 수 있음.
- 범위 밖 예측: 관측되지 않은 범위에서의 추정은 위험.
'LG U+ Why Not SW Camp 8기 > 학습 로그' 카테고리의 다른 글
| 공부 일지 #28 | 머신러닝 첫걸음: 개념, 유형, 흐름 (1) | 2025.09.03 |
|---|---|
| 공부 일지 #27 | 통계 및 실습: 회귀(복습), 로지스틱회귀 (1) | 2025.09.02 |
| 공부 일지 #25 | 추론과 검정 정리: 추정, 가설검정, t-test, ANOVA, 카이제곱 (4) | 2025.08.24 |
| 공부 일지 #24 | Python_Visualization 연습: Matplotlib & Pandas (4) | 2025.08.19 |
| 공부 일지 #23 | Python Pandas 데이터 분석 기초 함수 (0) | 2025.08.19 |
