학습날짜: 2025.09.03 ~ 2025.09.04
1. 과대적합과 과소적합
1.1. 머신러닝의 목표
: 머신러닝의 핵심 목표는 표본 데이터를 기반으로 일반화가 잘 되는 모델을 만드는 것
- 일반화(Generalization): 이전에 학습하지 않은 새로운 데이터에서 얼마나 잘 예측하는가
- 최적화(Optimization): 훈련 데이터에서 최고의 성능을 내도록 모델을 조정하는 과정
1.2. 과대적합(overfitting)
- 정의: 학습 데이터에 지나치게 맞춰져서 새로운 데이터를 예측하지 못하는 현상. 즉, 일반화의 오류
- 특징:
- 모델의 복잡도가 높은 상태
- 훈련 데이터의 정확도는 높지만 테스트 데이터 정확도는 낮음
- High variance, Low bias, 정확도와 관련 있음
- Variance : 예측값 ŷ 이 얼마나 흩어져 있는가. 입력데이터에 대해 모델이 얼마나 민감한가
- Bias: ŷ - y, 얼머나 다른가? ⇒ 오차
- 과대적합을 해결하는 것이 더 중요!
- 해결 방법
- 학습 데이터 추가 → 교차 검증(cross validation)
- 모델의 복잡도 줄이기 (Feature 제거 및 변환, 규제 기법 사용)
- 학습 데이터의 모델 노출 횟수 줄이기
1.3. 과소적합(underfitting)
- 정의: 모델이 충분히 학습되지 않아 데이터의 패턴을 제대로 잡지 못하는 현상. 즉, 최적화의 오류
- 특징:
- 모델의 복잡도가 지나치게 낮은 상태
- 훈련 데이터와 테스트 데이터 모두 정확도 낮음
- Low variance, High bias, 일부 특성만 반영
- 해결 방법
- 학습 시간을 늘림
- 모델을 새로 구축
- 모델의 복잡도 증가 (Feature 추가, 규제 기법 제거)
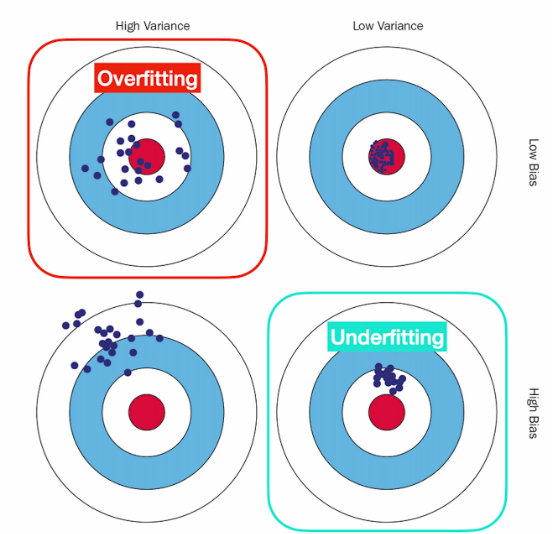
👉 (요약) 머신러닝 학습의 목표
: 과대적합(overfitting)과 과소적합(underfitting) 사이의 격차 최소화.
: 최적화와 일반화라는 기치에서 적절한 균형을 찾도록 학습되어야 함.

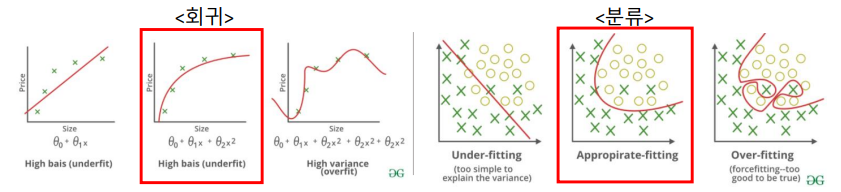
2. Feature Engineering
- 과대적합·과소적합 해결을 위한 접근
2.1. 정의
Feature Engineering은 원시 데이터(raw data)를 더 잘 표현할 수 있는 특징(feature)으로 변환하는 과정.
이는 단순히 데이터를 그대로 사용하는 것보다 더 나은 예측 성능을 내는 데 도움을 줌.
2.2. Feature Engineering의 필요성
- More flexibility: 모델 특성에 맞도록 데이터 변형 가능
- Simple models: 전처리를 통해 변수 수를 줄여 모델 단순화 (변수들이 100개 → 10개로 함축)
- Better results: 더 좋은 예측 성능 확보
👉 따라서 과대적합 상황에서는 불필요한 feature 제거를 통해 모델을 단순화할 수 있고, 과소적합 상황에서는 유의미한 feature 추가로 모델 성능을 개선할 수 있음!
2.3. Feature Selection (특징 선택)
특징의 중요도를 평가해 모델에 포함할지 여부를 결정하는 과정
- 방법:
- 통계 기반: 상관계수, 회귀 계수, p-value (변수들의 영향력 수치화하여 변수들의 유의성을 검정)
- 모델 기반: 의사결정나무 feature importance, SFS(Sequential Feature Selection)
- 도메인 지식 활용
2.4. Feature가 많을 때 문제점
- 차원의 저주: 차원이 늘어나면 데이터 밀도가 희석되어 특징이 사라짐 → 변수처리속도 저하
- 과적합 위험: feature가 많을수록 모델 복잡도가 증가
- 상관성 파악 어려움: 다중공선성 문제 발생
2.5. 해결 방법
- 규제화 적용 (L1, L2 정규화)
- 상관분석을 통한 Y에 영향을 적게 미치는 변수 제거
- 모델 기반 feature selection
(Feature Importance를 이용해 중요도가 낮은 변수제거, SFS를 이용 등) - 도메인 지식 반영
3. 데이터 인코딩 - 라벨인코딩, 원핫인코딩
3.1. 데이터 인코딩
사이킷런의 머신러닝 알고리즘은 범주형 데이터를 직접 입력받을 수 없으므로, 수치형 데이터로 변환하는 과정이 필요!
- 범주형 데이터?
- 범주 또는 항목의 형태로 표현되는 데이터 (예: 성별, 국적, 거주 지역 등)
- 숫자로 표현될 수 있으나 수치적 의미는 없음
- 사이킷런을 활용한 데이터 인코딩 절차:
- 대상 데이터 확인
- 인코더 클래스 객체 생성 (LabelEncoder / OneHotEncoder)
- .fit() 메소드로 인코딩할 데이터 학습
- .transform() 메소드로 데이터 변환
3.2. 라벨 인코딩 (Label Encoding)
라벨 인코딩은 범주형 데이터를 연속된 숫자로 변환하는 전처리 기법
- 순서가 존재할 때, 즉 순서 척도 데이터에서 주로 사용함.
- 예: 학년(1학년, 2학년, 3학년) → 0, 1, 2
# 데이터 불러오기 및 인코딩할 데이터 확인
import seaborn as sns
tips = sns.load_dataset('tips')
tips.head()
'''
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
'day': 'Thur', 'Fir', 'Sat', 'Sun'가 있음. → 데이터 인코딩하기
'''
# Label Encoding을 위한 라이브러리 불러오기
from sklearn.preprocessing import LabelEncoder
# Label Encoder 객체 생성
encoder = LabelEncoder()
# .fit 메소드에 인코딩할 데이터 전달(Encoding)
encoder.fit(tips['day'])
print(encoder.classes_)
'''
['Fri' 'Sat' 'Sun' 'Thur']
따라서 Fri → 0, Sat → 1, Sun → 2, Thur → 3 으로 라벨 인코딩 됨.
'''
# .transform 메소드를 통해 데이터 변환
labels = encoder.transform(tips['day'])3.3. 원핫 인코딩 (One-Hot Encoding)
원핫 인코딩은 범주형 데이터를 0과 1로 이루어진 배열로 변환하는 기법으로, 더미 코딩(dummy coding)과 동일.
- 카테고리 개수만큼 배열을 만들고, 해당 위치만 1로 표시하고 나머지는 모두 0으로 둠.
- 순서가 없는 범주(명목척도) 데이터에 적합
- 예: 성별(남, 여) → [1, 0], [0, 1]
👉 순서가 없는 데이터를 라벨 인코딩만 하면 “남성(1) > 여성(0)”처럼 잘못된 순서 관계를 모델이 학습할 수 있음. 이를 방지하기 위해 원핫 인코딩을 적용.
# !!!명목척도 => 전처리 => one-hot enc!!!
# One-Hot Encoding을 위한 라이브러리 불러오기
from sklearn.preprocessing import OneHotEncoder
# One-Hot Encoder 객체 생성
encoder = OneHotEncoder()
# 2차원 데이터로 변환 why? OneHotEncoder는 2차원 데이터만 입력받으므로!
labels = labels.reshape(-1, 1) # 2-dimension으로 넣어줘야 하므로 reshape(-1, 1) 해줌
# .fit_transform 메소드에 인코딩할 **데이터 전달 및 데이터 변환**
one_hot_result = encoder.fit_transform(labels)
# 변환된 데이터 확인
one_hot_result
'''
<Compressed Sparse Row sparse matrix of dtype 'float64'
with 244 stored elements and shape (244, 4)>
'''4. 데이터 스케일링 - 표준화, 정규화
4.1. 데이터 스케일링
현실의 데이터는 크기, 단위, 범위가 서로 다른 경우가 많음. 이런 차이가 있으면:
- KNN 같은 거리 기반 알고리즘에서 오류가 발생할 수 있음.
- 스케일이 큰 특성 위주로 모델이 학습될 수 있음.
👉 따라서, 데이터를 일정한 기준으로 맞추는 스케일링이 필요함.
- 사이킷런을 활용한 스케일링 절차:
- 대상 feature 데이터 확인
- 스케일러 객체 생성 (예: StandardScaler, MinMaxScaler)
- .fit_transform() 메소드로 데이터 분포 분석 및 스케일링 정보 저장 + 데이터 변환
4.1. 표준화(Z-score Normalization)
- 평균이 0, 분산이 1이 되도록 데이터의 배율 조정
- 서로 다른 단위의 데이터를 비교 가능하게 함
# 데이터 불러오기
df_bike = df.loc[:, 'temp':'windspeed']
df_bike.head()
'''
temp atemp humidity windspeed
0 9.84 14.395 81 0.0000
1 9.02 13.635 80 0.0000
2 9.02 13.635 80 0.0000
3 9.84 14.395 75 .0000
4 9.84 14.395 75 0.0000
'''
# Z-scaling(Z-normalization) 라이브러리 불러오기
from sklearn.preprocessing import StandardScaler
# Z-normalization 객체 생성
scaler = StandardScaler()
# .fit_transform() 메소드로 데이터 분포 분석 및 스케일링 정보 저장 + 데이터 변환
scaled_arr = scaler.fit_transform(df_bike)
# 결과 확인
scaled_arr # array 반환됨!
'''
array([[-1.33366069, -1.09273697, 0.99321305, -1.56775367],
[-1.43890721, -1.18242083, 0.94124921, -1.56775367],
[-1.43890721, -1.18242083, 0.94124921, -1.56775367],
...,
[-0.80742813, -0.91395927, -0.04606385, 0.26970368],
[-0.80742813, -0.73518157, -0.04606385, -0.83244247],
[-0.91267464, -0.82486544, 0.21375537, -0.46560752]])
'''
# 데이터프레임으로 변환
df_bike_z = pd.DataFrame(scaled_arr, columns=df_bike.columns)
df_bike_z.head()
'''
temp atemp humidity windspeed
0 -1.333661 -1.092737 0.993213 -1.567754
1 -1.438907 -1.182421 0.941249 -1.567754
2 -1.438907 -1.182421 0.941249 -1.567754
3 -1.333661 -1.092737 0.681430 -1.567754
4 -1.333661 -1.092737 0.681430 -1.567754
'''4.2. 정규화(Min-Max Scaling)
- 데이터를 0~1 범위로 변환하는 방식
- 서로 다른 스케일의 데이터를 동일한 기준으로 맞춤
- ⚠️ 이상치(outlier)가 있으면 스케일이 왜곡될 수 있으므로 주의해야 함 ⇒ 이상치 유무 확인 꼭!!
# Min-Max scaling 라이브러리 불러오기
from sklearn.preprocessing import MinMaxScaler
# Min-Max scaling 객체 생성
mm_scaler = MinMaxScaler()
# .fit_transform() 메소드로 데이터 분포 분석 및 스케일링 정보 저장 + 데이터 변환
scaled_arr = mm_scaler.fit_transform(df_bike)
# 결과 확인 - 배열로 반환됨!
scaled_arr
'''
array([[0.2244898 , 0.30506768, 0.81 , 0. ],
[0.20408163, 0.28806354, 0.8 , 0. ],
[0.20408163, 0.28806354, 0.8 , 0. ],
...,
[0.32653061, 0.33896409, 0.61 , 0.26319502],
[0.32653061, 0.3728605 , 0.61 , 0.10532503],
[0.30612245, 0.35585636, 0.66 , 0.15786999]])
'''
# 데이터프레임으로 변환
df_bike_mm = pd.DataFrame(scaled_arr, columns=df_bike.columns)
df_bike_mm.head()
'''
temp atemp humidity windspeed
0 0.224490 0.305068 0.81 0.000000
1 0.204082 0.288064 0.80 0.000000
2 0.204082 0.288064 0.80 0.000000
3 0.224490 0.305068 0.75 0.000000
4 0.224490 0.305068 0.75 0.000000
'''4.3. 스케일링시 주의사항
- 이상치 제거 후에 스케일링 하는 것이 좋음
- 각 feature 별 특성을 고려해 서로 다른 스케일러 사용해도 OK!
- y값인 target(label) 데이터는 별도의 스케일링을 진행하지 않음
👉 전체적으로, 데이터 인코딩과 스케일링은 머신러닝 모델 성능에 직접적인 영향을 주는 중요한 전처리 과정임.
'LG U+ Why Not SW Camp 8기 > 학습 로그' 카테고리의 다른 글
| 공부 일지 #32 | 머신러닝: 회귀 (0) | 2025.09.07 |
|---|---|
| 공부 일지 #31 | 머신러닝 전처리: 불균형 데이터·이상치·결측치 처리 (0) | 2025.09.07 |
| 공부 일지 #29 | 머신러닝 경험해보기: KNN 알고리즘 (0) | 2025.09.05 |
| 공부 일지 #28 | 머신러닝 첫걸음: 개념, 유형, 흐름 (1) | 2025.09.03 |
| 공부 일지 #27 | 통계 및 실습: 회귀(복습), 로지스틱회귀 (1) | 2025.09.02 |
