학습날짜: 2025.09.04
1. 회귀(Regression)란?
- 정의: 독립변수(X)와 종속변수(Y)의 관계를 설명하고 예측하는 통계적 기법.
- 다중선형회귀
- 독립변수가 여러 개인 경우를 의미
- 목표: 종속변수를 가장 잘 설명할 수 있는 최적의 계수를 찾는 것.

2. 회귀 추정 접근 방식
- 최소제곱법 (OLS, Ordinary Least Squares) - 통계학적 접근
- 예측값과 실제값 차이(잔차)의 제곱합을 최소화하는 계수를 찾음.
- 최대우도추정 (MLE, Maximum Likelihood Estimation) - 확률적 접근(통계학, 머신러닝 공통)
- 데이터가 주어진 확률분포에서 나올 가능도를 최대화하는 계수를 찾음.
- 선형회귀에서 오차항이 정규분포라고 가정하면, MLE와 OLS가 동일한 해를 줌.
- 경사하강법 (Gradient Descent) - 머신러닝 접근
- 목적 함수(예: MSE, 로그우도)를 직접 풀 수 없을 때 사용하는 수치적 최적화 기법.
- 기울기(gradient)를 따라 조금씩 이동하며 최소값을 찾음.
- 복잡한 머신러닝 모델(딥러닝 포함)에서 주로 사용.
3. 경사하강법 (Gradient Descent) 과정
3.1. 손실 함수 (Loss function)
- 선형 회귀(linear regression)에서, 예측값은

- 손실 함수 MSE(Mean Squared Error)는

3.2. 기울기(Gradient) 계산
- 손실 함수를 (w) 와 (b)에 대해 각각 편미분하면,

- 기울기는 손실 함수를 줄이기 위해 어느 방향으로 이동해야 하는지를 알려줌
3.3. 최소하강법 업데이트 규칙
- 각 단계에서 (w) 와 (b)를 업데이트하는 식은

- 여기서, ɑ = learning rate (학습률, 한 번에 얼마나 이동할지 결정하는 값)
3.4. 업데이트 반복
- 초기값: w, b
- 반복(iteration)마다

- 기울기(gradient)가 알려주는 내리막 방향으로 조금씩 이동하면서 아래 수식의 값을 찾게 됨 = w,b의 최적 값 발견!
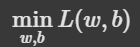
4. 단순 선형회귀 실습 절차 (sklearn)
4.1. 데이터 준비
import pandas as pd
boston = pd.read_csv(path)
boston.head()
'''
TOWN LON LAT CMEDV CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX PTRATIO B LSTAT
0 Nahant -70.9550 42.2550 24.0 0.00632 18.0 2.31 0 0.538 6.575 65.2 4.0900 1 296 15.3 396.90 4.98
1 Swampscott -70.9500 42.2875 21.6 0.02731 0.0 7.07 0 0.469 6.421 78.9 4.9671 2 242 17.8 396.90 9.14
2 Swampscott -70.9360 42.2830 34.7 0.02729 0.0 7.07 0 0.469 7.185 61.1 4.9671 2 242 17.8 392.83 4.03
3 Marblehead -70.9280 42.2930 33.4 0.03237 0.0 2.18 0 0.458 6.998 45.8 6.0622 3 222 18.7 394.63 2.94
4 Marblehead -70.9220 42.2980 36.2 0.06905 0.0 2.18 0 0.458 7.147 54.2 6.0622 3 222 18.7 396.90 5.33
'''4.2. LinearRegression() 객체 생성
# 단순 선형회귀모델
X = boston["RM"] # 독립변수: 주택의 평균 방 개수
y = boston["CMEDV"] # 종속변수: 주택 가격 중앙값
# scikit-learn의 회귀 학습은 (n_samples, n_features) 형태의 2차원 배열을 입력으로 요구!
# X 확인
print(X.values.ndim)
'''
출력값: 1
'''
# 1차원 → 2차원으로 변환 (열 벡터 형태로 맞춰줌)
X = X.values.reshape(-1, 1)
# 선형회귀 라이브러리 불러오기
from sklearn.linear_model import LinearRegression
# 선형회귀 모델 객체 생성
rg = LinearRegression()4.3. .fit(X_train, y_train)으로 모델 학습
#학습
rg.fit(X, y)
4.4. .predict(X_test)로 예측 수행
# 학습된 모델을 통해 집값 예측해보기
import numpy as np
# 테스트 데이터 생성
test_data = np.linspace(min(X), max(X))
# 데이터 형태 확인 (50행 1열, 즉 2차원 배열이어야 scikit-learn에서 처리 가능)
test_data.shape
'''
(50, 1)
'''
# 학습된 회귀모델을 사용하여 예측값 계산
y_pred = rg.predict(test_data)
print(y_pred) # 배열 형태로 출력됨
'''
[-2.25531945 -1.28611178 -0.31690411 0.65230357 1.62151124 2.59071891
3.55992658 4.52913426 5.49834193 6.4675496 7.43675728 8.40596495
...
38.45140281 39.42061048 40.38981815 41.35902583 42.3282335 43.29744117
44.26664885 45.23585652]
'''
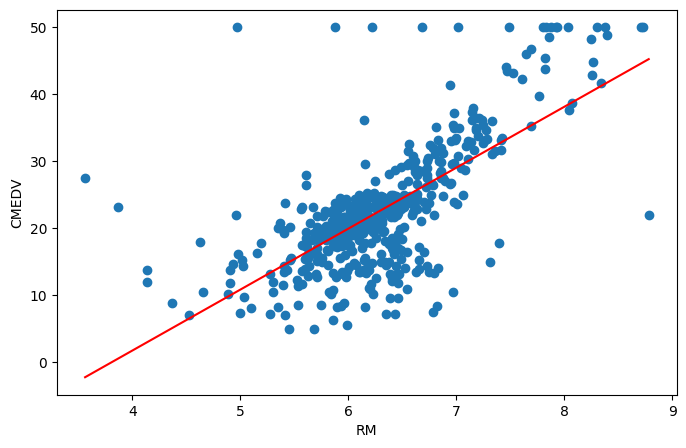
# 학습된 회귀선 그려보기
plt.figure(figsize=(8, 5))
plt.scatter(X, y)
plt.plot(test_data, y_pred, "r")
plt.xlabel("RM")
plt.ylabel("CMEDV")
plt.show()
'''
참고: scikit-learn의 ML 회귀모형에는 통계 패키지(statsmodels)처럼 summary() 메소드가 없음.
즉, 계수의 유의성 검정이나 t-통계량, p-value 등을 자동으로 제공하지 않음.
┌─> ML 모형 (scikit-learn) ──> predict (예측값 산출)
data───|
└─> 통계 모형 (statsmodels) ──> summary (추정치 + 통계적 유의성)
'''
5. 다중 선형 회귀
# 다중 선형회귀 (단순 선형회귀와 동일한 Boston 데이터 사용)
# 독립변수(X): 주택 관련 여러 컬럼 (5번째 열부터 끝까지)
# 종속변수(y): 주택 가격 중앙값(CMEDV)
cols = list(boston.columns[4:])
X = boston[cols]
y = boston["CMEDV"]
# 학습과 테스트 데이터셋 나누기 (라이브러리 사용)
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, random_state=47, test_size=0.3)
x_train.shape, y_train.shape
# 선형회귀 모델 객체 생성 (단순회귀와 동일한 클래스 사용)
rg = LinearRegression()
# 모델 학습
rg.fit(x_train, y_train)
# 테스트 데이터에 대해 예측 수행
y_pred = rg.predict(x_test)
y_pred # 배열로 나옴
'''
array([15.84777959, 32.38854674, 24.49119891, 30.96899051, 27.28271258,
19.77383117, 23.31833253, 31.93340866, 32.62804291, 22.77194181,
...
23.66823476, 17.22098502, 18.44027163, 30.16838738, 34.46470416,
23.06886431, 37.60399324])
'''
# 회귀 계수 확인 (각 독립변수에 대응되는 회귀계수)
np.round(rg.coef_, 1)
'''
array([ -0.1, 0. , 0. , 3.7, -16.3, 4.8, -0. , -1.5, 0.3,
-0. , -0.9, 0. , -0.4])
중요: scaling을 안했기 때문에 이 값 그대로 믿으면 안됨!
'''
# 회귀 계수가 대응되는 독립변수명 확인
boston.columns[4:]
'''
Index(['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX',
'PTRATIO', 'B', 'LSTAT'],
dtype='object')
'''6. 회귀 모델 평가 지표
- 손실 함수 (Loss Function)
- RSS, SSE, MSE 등
- 오차가 작을수록 모델 성능이 좋음

# 지표 값 구하는 라이브러리 불러오기
from sklearn import metrics
# 회귀분석모델의 성능 지표 ⇒ MSE, RMSE, MAE, MAPE
mse = metrics.mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mae = metrics.mean_absolute_error(y_test, y_pred)
mape = metrics.mean_absolute_percentage_error(y_test, y_pred)
print(mse, rmse, mae, mape)
'''
25.932628232945508 5.092408883126482 3.172101967431917 0.14869247400544292
'''- 결정계수 (R²)
- 모델 설명력을 나타내는 지표
- 0 ~ 1 사이 값, 1에 가까울수록 설명력 ↑
'LG U+ Why Not SW Camp 8기 > 학습 로그' 카테고리의 다른 글
| 공부 일지 #34 | 머신러닝: 성능지표(ROC·AUC)와 Decision Tree (0) | 2025.09.11 |
|---|---|
| 공부 일지 #33 | 머신러닝 : 규제와 분류(로지스틱, 성능지표) (0) | 2025.09.07 |
| 공부 일지 #31 | 머신러닝 전처리: 불균형 데이터·이상치·결측치 처리 (0) | 2025.09.07 |
| 공부 일지 #30 | 머신러닝 전처리: 과대적합·과소적합, 인코딩, 스케일링 (0) | 2025.09.07 |
| 공부 일지 #29 | 머신러닝 경험해보기: KNN 알고리즘 (0) | 2025.09.05 |
