학습 날짜: 2025.09.05
1. 규제 기법의 이해
머신러닝 모델은 학습 데이터에 과도하게 맞춰지는 과대적합(overfitting) 문제가 발생함.
이를 방지하기 위해 규제 기법 사용
- 규제: 손실 함수에 패널티 항 추가해 회귀 계수(가중치) 크기 제어하는 방식
- α(알파): 규제 강도 조절하는 하이퍼파라미터
- α가 작음 (≈ 0)
- 규제 항 영향 거의 없음
- 모델이 RSS에만 집중(= 잔차 최소화에만 집중) → 계수가 크게 커질 수 있음
- 모델이 데이터에 과도하게 맞춰짐 → 복잡도 ↑, 과대적합 위험 ↑
- α가 큼 (→ ∞)
- 규제 항 영향 매우 큼
- 계수 w 값이 0에 근사하도록 강하게 압박
- 모델 단순해짐 → 복잡도 ↓, 과소적합 위험 ↑
- α가 작음 (≈ 0)
결국 규제는 모델 복잡도 낮춰 과대적합 완화하는 방법임

2. 릿지 회귀 (Ridge Regression, L2 규제)

- 회귀 계수 제곱합에 패널티 부여
- 계수 크기를 줄여 과대적합 완화
- 단, 계수가 정확히 0이 되지는 않음
# boston 데이터셋 사용 (데이터 불러오는 과정 생략)
# train/test 데이터 분할
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(df.iloc[:,4:], # 독립변수
df['CMEDV'], # 종속변수
test_size=0.3, # 30%를 test로 분리
random_state=12)
x_train.shape, x_test.shape, y_train.shape, y_test.shape
# 릿지를 위한 라이브러리 불러오기
from sklearn.linear_model import Ridge
# 규제를 위한 alpha 값 지정
alpha = 0.1
# Rigde 클래스 객체 생성
ridge = Ridge(alpha=alpha)
# 규제 학습 수행
ridge.fit(x_train, y_train)
# 학습된 모델로 예측
ridge_pred = ridge.predict(x_test)
# 학습/테스트 데이터셋 R^2 계산 (설명력 지표)
r2_train = ridge.score(x_train, y_train)
r2_test = ridge.score(x_test, y_test)
print(f'Training-dataset R2: {r2_train: .3f}')
print(f'Test-dataset R2: {r2_test: .3f}')
'''
Training-dataset R2: 0.751
Test-dataset R2: 0.715
'''
# 컬럼별 회귀계수 확인 (Series 형태로 저장)
ridge_coef_table = pd.Series(data = np.round(ridge.coef_, 1),
index=feature_names)
print('Ridge Regression Coefficients: ')
print(ridge_coef_table.sort_values(ascending=False))
'''
Ridge Regression Coefficients:
RM 3.6
CHAS 3.3
RAD 0.3
INDUS 0.1
ZN 0.1
B 0.0
TAX -0.0
AGE 0.0
CRIM -0.1
LSTAT -0.6
PTRATIO -0.8
DIS -1.3
NOX -15.8
dtype: float64
'''
# 각 독립변수에 대한 회귀계수 시각화
plt.figure(figsize=(10, 5))
ridge_coef_table.plot(kind='bar')
plt.ylim(-12, 5)
plt.show()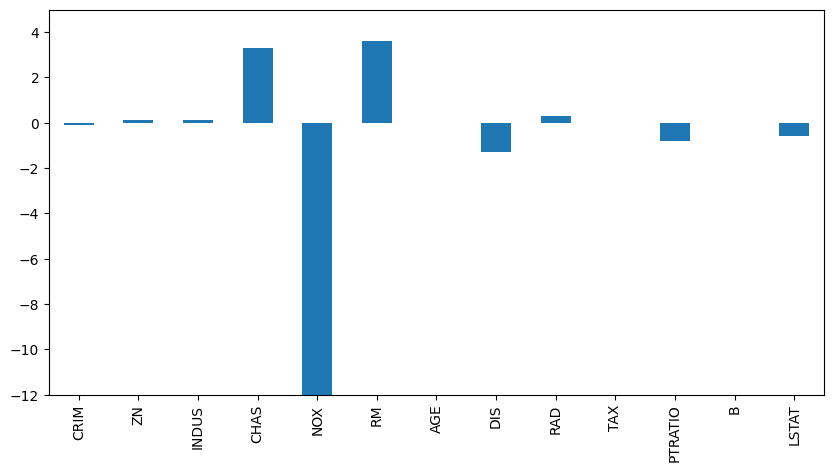
from sklearn import metrics
# alpha 값 변화에 따른 성능 비교
alphas = [0, 0.1, 0.12, 0.2, 0.5, 1, 10]
for a in alphas:
# 릿지 회귀 모델 생성 및 학습
ridge = Ridge(alpha = a)
ridge.fit(x_train, y_train)
ridge_y_pred = ridge.predict(x_test)
# MSE, RMSE 지표 계산
mse = metrics.mean_squared_error(y_test, ridge_y_pred)
rmse = np.sqrt(mse)
# 데이터셋별 R^2 지표 계산
r2_train = ridge.score(x_train, y_train)
r2_test = ridge.score(x_test, y_test)
# 성능지표 출력
print(f'Alpha: {a: .3f}, R2(train): {r2_train: .3f}, R2(test): {r2_test: .3f}, MSE: {mse: .3f}, RMSE: {rmse: .3f}')
'''
Alpha: 0.000, R2(train): 0.751, R2(test): 0.715, MSE: 24.674, RMSE: 4.967
Alpha: 0.100, R2(train): 0.751, R2(test): 0.715, MSE: 24.708, RMSE: 4.971
Alpha: 0.120, R2(train): 0.751, R2(test): 0.715, MSE: 24.716, RMSE: 4.972
Alpha: 0.200, R2(train): 0.751, R2(test): 0.715, MSE: 24.750, RMSE: 4.975
Alpha: 0.500, R2(train): 0.750, R2(test): 0.713, MSE: 24.886, RMSE: 4.989
Alpha: 1.000, R2(train): 0.749, R2(test): 0.711, MSE: 25.080, RMSE: 5.008
Alpha: 10.000, R2(train): 0.741, R2(test): 0.702, MSE: 25.828, RMSE: 5.082
∴ 이 데이터셋에서는 α=0~0.2 정도가 적절
'''
👉 α 값에 대한 정리
- α = 0 → 규제 없는 일반 선형회귀 → 과대적합 위험 있음
- α 작을 때 → 성능 유지하면서 규제 효과 조금 있음 → Best
- α 클 때 → 모델 단순해져 성능 저하
3. 라쏘 회귀 (Lasso Regression, L1 규제)
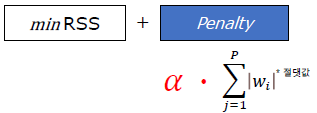
- 회귀 계수 절댓값에 패널티 부여
- 불필요한 변수 계수를 0 에 근사하도록 만들어 과대적합 개선
- 중요하지 않은 변수는 아예 빼버리기 때문에 변수 선택(Feature Selection) 효과 있음
4. 분류(Classification)의 이해
- 예측 값이 범주형 데이터일 때 사용
- 이진 분류의 경우, 데이터가 특정 클래스에 속할 확률(0~1)을 예측
- 대표적인 지도학습 방법: 로지스틱 회귀(Logistic Regression)

5. 분류를 위한 로지스틱 회귀의 이해
- 선형 회귀 방식을 분류 문제에 적용
- 주로 이진 분류 문제에 사용, 다중 클래스에도 확장 가능
- 시그모이드 함수 사용해 확률(0~1)로 변환
5.1. 시그모이드 함수
- 선형 회귀식을 시그모이드 함수의 입력값으로 넣어 분류 모델에 사용
- 출력값(0~1)을 확률로 간주해 분류
- 임계값(threshold, 보통 0.5)에 따라 Positive / Negative 구분 → 임계값 기반 분류

- 예시: 암 진단 문제
- Positive = 암 환자
- Negative = 정상 환자
- 일반적으로 데이터 적은 쪽을 Positive로 설정 → 그게 안정적임
- 반대로 설정하면 경계가 모호해지고 분류 성능 떨어질 수 있음
- 분류 정확도가 높은 회귀선 찾는 것이 중요!
# 필요한 라이브러리 불러오기
from sklearn.preprocessing import StandardScaler # 스케일링
from sklearn.model_selection import train_test_split # 데이터셋 분할
from sklearn.linear_model import LogisticRegression # 로지스틱 회귀
# 데이터 불러오기
path = "/content/drive/MyDrive/2025 LG U+ 8기/ML/dataset/bike-demand.csv"
df_bike = pd.read_csv(path)
df_bike.head()
'''
datetime season holiday workingday weather temp atemp humidity windspeed casual registered count
0 2011-01-01 00:00:00 1 0 0 1 9.84 14.395 81 0.0 3 13 16
1 2011-01-01 01:00:00 1 0 0 1 9.02 13.635 80 0.0 8 32 40
2 2011-01-01 02:00:00 1 0 0 1 9.02 13.635 80 0.0 5 27 32
3 2011-01-01 03:00:00 1 0 0 1 9.84 14.395 75 0.0 3 10 13
4 2011-01-01 04:00:00 1 0 0 1 9.84 14.395 75 0.0 0 1 1
'''
# 독립변수 데이터 생성
# temp, atemp, humidity, windspeed 컬럼만 선택 → 날씨 관련 변수만 사용
X_df_bike = df_bike.iloc[:, 5:9]
X_df_bike.head()
# 종속변수 데이터를 위한 파생변수 생성
# 총 대여 건수(count)가 500 이상이면 1, 미만이면 0 → 이진 분류 문제로 변환
cond = (df_bike['count'] < 500)
df_bike['y'] = np.where(cond, 0, 1)
y = df_bike['y']
# StandardScaler 이용한 스케일링
# 변수 단위(온도, 습도, 풍속 등)가 달라서 스케일 조정 필요
scaler = StandardScaler()
scaler.fit(X_df_bike)
result = scaler.transform(X_df_bike)
# 스케일된 결과 데이터를 DataFrame으로 저장
X_scaled_bike = pd.DataFrame(data = result,
columns = X_df_bike.columns)
X_scaled_bike.head()
'''
temp atemp humidity windspeed
0 -1.333661 -1.092737 0.993213 -1.567754
1 -1.438907 -1.182421 0.941249 -1.567754
2 -1.438907 -1.182421 0.941249 -1.567754
3 -1.333661 -1.092737 0.681430 -1.567754
4 -1.333661 -1.092737 0.681430 -1.567754
'''
# 데이터셋 분리 (train: 70%, test: 30%)
x_train, x_test, y_train, y_test = train_test_split(X_scaled_bike, y,
test_size=0.3,
random_state=12)
x_train.shape, x_test.shape, y_train.shape, y_test.shape
'''
((7620, 4), (3266, 4), (7620,), (3266,))
'''
# LogisticRegression 모델 객체 생성 / 기본 하이퍼파라미터 사용
clf = LogisticRegression()
# 훈련 데이터를 이용한 학습
clf.fit(x_train, y_train)
# 학습된 모델에 테스트 데이터를 이용하여 예측값 생성
y_pred = clf.predict(x_test)
# score 메소드를 통한 정확도 측정(train / test)
train_score = clf.score(x_train, y_train)
test_score = clf.score(x_test, y_test)
print(f'Training Data Accuracty: {train_score: .3f}')
print(f'Testing Data Accuracty: {test_score: .3f}')
'''
Training Data Accuracty: 0.927
Testing Data Accuracty: 0.924
'''5.2. 비용 함수(Cost Function)
- 로지스틱 회귀는 평균제곱오차(MSE) 대신 크로스 엔트로피(Cross-Entropy) 사용
- 크로스 엔트로피(Cross-Entropy) ? 모델에서 예측한 확률값이 실제값과 비교했을 때 틀릴 수 있는 정보량

- Y = 1일 때 (파란 곡선)
- 예측 확률 ŷ → 에 가까워질수록 Loss → 0 (패널티 없음)
- 예측 확률 ŷ → 에 가까워질수록 Loss → ∞ (엄청난 패널티)
- Y = 0일 때 (빨간 곡선)
- 예측 확률 ŷ → 에 가까워질수록 Loss → 0 (패널티 없음)
- 예측 확률 ŷ → 에 가까워질수록 Loss → ∞ (엄청난 패널티)
- 따라서 모델은 잘못된 방향의 확률 예측에 큰 패널티 부여
👉 분류의 로지스틱 회귀분석 내용 정리
- ŷ 은 logit 확률로부터 도출한 class 값
- 회귀계수들은 해당 독립변수가 값이 1단위 증가시 odds만큼 변화함
- cost function은 cross-entropy
6. 분류 모델의 평가
6.1. 성능지표 기본 이해
- 데이터셋
- Test: 실제 정답이 되는 데이터셋(Y)
- Predict : 모델이 예측한 결과인 데이터셋(Ŷ)
- 데이터의 종류
- Positive : 모델을 통해 알아내고 싶은 목적 값(1)
- Negative : Positive가 아닌 값(0)
- 모델의 분류 결과
- True : Y = Ŷ → 예측성공
- False : Y ≠ Ŷ → 예측 실패
6.2. 정확도(Accuracy)
- 전체 예측 중 맞춘 비율
- False 예측(FP, FN)을 고려하지 않기 때문에 항상 좋은 지표라 보기 어려움.

6.3. 정밀도(Precision)
- 모델이 Positive라고 예측한 것 중 실제 Positive의 비율
- 즉, 정답이 아닌 것(FP)을 얼마나 줄였는가
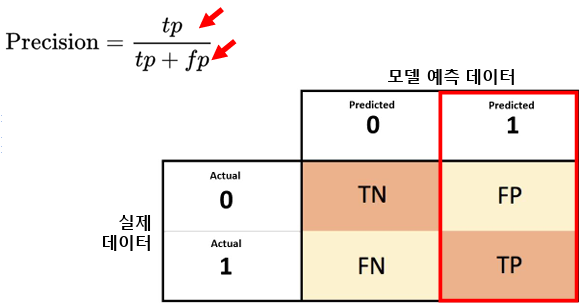
6.4. 재현율(Recall)
- 실제 Positive 중에서 맞게 예측한 비율
- 즉, 실제 정답을 얼마나 많이 선택하는 가
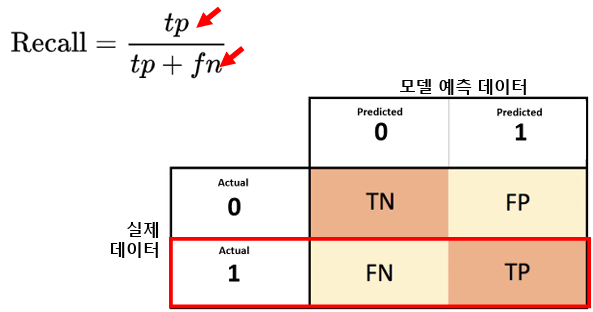
6.5. 정밀도와 재현율
- 상황에 따라 중요도 다름
- 암 진단 → 재현율 중요 (놓치면 안 됨)
- 스팸 필터링 → 정밀도 중요 (잘못 걸러내면 안 됨)
- 정밀도와 재현율의 함정
- 임계값(threshold)을 극히 작게 하면, 양성 예측이 과도하게 늘어나서 재현율 100% 달성 가능
- 하지만 이는 단순한 수치 조작에 불과함
- 따라서 threshold를 임의로 건드려 성능을 부풀리는 건 의미 없음
- F1 Score 필요성
- 정밀도와 재현율의 조화평균(Harmonic Mean)으로 계산
- 정밀도와 재현율을 동시에 고려하는 지표
- 모델 튜닝 시 F1 Score 상승을 목표로 하는 것이 바람직함

# 분류 모델을 위한 성능지표 함수 로딩
from sklearn.metrics import confusion_matrix # 오차 행렬
from sklearn.metrics import accuracy_score # 정확도
from sklearn.metrics import precision_score # 정밀도
from sklearn.metrics import recall_score # 재현율
# 오차 행렬 생성
# y_test = 실제값, y_pred = 예측값
# 행: 실제 클래스(0,1), 열: 예측 클래스(0,1)
confusion = confusion_matrix(y_test, y_pred)
confusion
'''
array([[3018, 0],
[ 248, 0]])
'''
# 정확도, 정밀도, 재현율 계산
accuracy = accuracy_score(y_test, y_pred) # Accuracy: 전체 예측 중 맞춘 비율
precision = precision_score(y_test, y_pred) # Precision: Positive라고 예측한 것 중 실제 Positive 비율
recall = recall_score(y_test, y_pred) # Recall: 실제 Positive 중에서 맞게 예측한 비율
# 계산된 지표 출력
print(f'Accuracy: {accuracy: .4f}, Precision: {precision: .4f}, Recall: {recall: .4f}')
'''
Accuracy: 0.9241, Precision: 0.0000, Recall: 0.0000
'''
'LG U+ Why Not SW Camp 8기 > 학습 로그' 카테고리의 다른 글
| 공부 일지 #35 | 머신러닝: 앙상블과 RandomForest, 교차검증 (0) | 2025.09.14 |
|---|---|
| 공부 일지 #34 | 머신러닝: 성능지표(ROC·AUC)와 Decision Tree (0) | 2025.09.11 |
| 공부 일지 #32 | 머신러닝: 회귀 (0) | 2025.09.07 |
| 공부 일지 #31 | 머신러닝 전처리: 불균형 데이터·이상치·결측치 처리 (0) | 2025.09.07 |
| 공부 일지 #30 | 머신러닝 전처리: 과대적합·과소적합, 인코딩, 스케일링 (0) | 2025.09.07 |
