학습날짜: 2025.09.11
1. 차원 축소(Dimension Reduction)
- 차원의 저주
- 고차원 데이터 다룰 때 발생하는 현상임
- 동일한 데이터 양에서도 과적합 잘 생기고, 일반화 어려움
- 데이터 밀도 유지하려면 필요한 데이터 양이 기하급수적으로 늘어남
- 차원의 증가가 과적합에 미치는 영향
- 노이즈를 신호로 잘못 학습함
- 다중공선성 발생
- 데이터 희소화, 편중
- Occam’s Razor (오컴의 면도날)
- "불필요한 가정 세우지 말고, 최소한의 변수로 설명 가능한 모델이 바람직함"
- Feature Selection vs Extraction
- Feature Selection: 중요한 변수만 선택 (Forward/Backward Selection)
- Feature Extraction: 변수를 변환하거나 규제해 단순화 (PCA가 대표적, Ridge·Lasso·Elastic Net도 변수 영향력을 줄여 과적합 완화에 사용됨)
1.1. SFS (Sequential Forward Selection)
- Forward & Backward Selection 의 한 방법.
- 실무에서는 잘 쓰지 않음, 확인 용도로만 쓰임.
- 단계:
- 가장 좋은 feature 선택
- 다른 feature 추가 → pair 검증
- triplet 생성 후 검증
- 반복해서 feature set 완성
# SFS 실습; iris 데이터 사용
!pip install mlxtend --upgrade # SFS 구현을 위해 사용
from sklearn.neighbors import KNeighborsClassifier
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
# 분류 모델 생성 (KNN, k=5 사용)
knn = KNeighborsClassifier(n_neighbors=5)
# Sequential Feature Selector 설정
sfs1 = SFS(knn,
k_features=3, # 현재 특징 4개인데, 3개로 만들고 싶다.
forward=True, # True면 전진, False면 후진
floating=False, # 전진이면 무조건 이거 넣어야 함. 후진이면 삭제
verbose=2, # log level
scoring='accuracy', # 이것밖에 없음
cv = 0
)
# 모델 학습 (특징 선택 수행)
sfs1 = sfs1.fit(X, y)
'''
[Parallel(n_jobs=1)]: Done 4 out of 4 | elapsed: 0.0s finished
[2025-09-11 00:33:13] Features: 1/3 -- score: 0.96[Parallel(n_jobs=1)]: Done 3 out of 3 | elapsed: 0.0s finished
→ 첫 번째 feature 선택 후 정확도
[2025-09-11 00:33:13] Features: 2/3 -- score: 0.9666666666666667[Parallel(n_jobs=1)]: Done 2 out of 2 | elapsed: 0.0s finished
→ 두 번째 feature 추가 후 정확도
[2025-09-11 00:33:13] Features: 3/3 -- score: 0.9733333333333334
→ 세 번째 feature 추가 후 정확도
'''
# 어떤 feature가 들어가있길래 정확도가 향상될까??
sfs1.subsets_
'''
{1: {'feature_idx': (3,), → 첫 번째 선택된 feature는 인덱스 3번(=petal width)
'cv_scores': array([0.96]),
'avg_score': np.float64(0.96),
'feature_names': ('3',)},
2: {'feature_idx': (0, 3), → 0번(sepal length)과 3번(petal width)
'cv_scores': array([0.96666667]),
'avg_score': np.float64(0.9666666666666667),
'feature_names': ('0', '3')},
3: {'feature_idx': (0, 2, 3), → 최종 선택된 3개 feature는 sepal length, petal length, petal width
'cv_scores': array([0.97333333]),
'avg_score': np.float64(0.9733333333333334),
'feature_names': ('0', '2', '3')}}
'''
sfs1.k_score_ # np.float64(0.9733333333333334)
'''
Note:
mlxtend는 버전 업데이트가 잘 안 됨.
sklearn에도 있으니 그걸 사용해보자!
'''
# sklearn, loading과정이 자세히 보이진 않지만, 심플하게 사용 가능
from sklearn.feature_selection import SequentialFeatureSelector
# foward 선택
sfs_foward = SequentialFeatureSelector(knn, n_features_to_select=2, direction='forward')
sfs_foward.fit(X,y)
sfs_foward.get_support()
'''
array([False, False, True, True])
즉, petal length(2), petal width(3)가 선택됨
'''
# backward 선택
sfs_backward = SequentialFeatureSelector(knn, n_features_to_select=2, direction='backward')
sfs_backward.fit(X,y)
sfs_backward.get_support()
array([False, False, True, True])
전진 선택과 동일하게 petal length(2), petal width(3)가 선택됨
'''1.2. PCA (주성분 분석)
- 대표적 차원 축소 기법
- 공분산 큰 방향(정보량 많은 방향)으로 축 설정
- 데이터 정사영하여 차원 축소
- 첫 번째 주성분 → 이후 축은 직교(orthogonal)하게 결정
- 차원 과도 축소 시 정보 손실 발생
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# iris 데이터 준비; 스케일링
X = iris['data']
iris_z_score = StandardScaler().fit_transform(X)
# 주성분 분석 : 4차원 → 2차원으로 축소
pca = PCA(n_components=2)
pca.fit(iris_z_score)
# 주성분 찾기 : 고유벡터(축)
print(pca.components_.shape)
print(pca.components_)
'''
(2, 4)
[[ 0.52106591 -0.26934744 0.5804131 0.56485654]
[ 0.37741762 0.92329566 0.02449161 0.06694199]]
'''
# projection (정사영: 원 데이터를 새 축으로 변환)
X_pca = pca.transform(iris_z_score)
X_pca
'''
array([[-2.26470281, 0.4800266 ],
[-2.08096115, -0.67413356],
...
[ 1.37278779, 1.01125442],
[ 0.96065603, -0.02433167]])
⇒ 원래 4차원 데이터가 2차원 좌표(pca_com1, pca_com2)로 변환됨
⇒ 어떤 feature가 어떤 의미인지 직접 해석 불가 (PCA의 단점)
'''
# 각 주성분이 분산을 얼마나 잘 설명하는지?
np.sum(pca.explained_variance_ratio_)
'''
np.float64(0.9581320720000166)
⇒ 원래 정보의 약 95.8% 보존됨, 나머지 약 4.2% 손실
'''
# PCA 결과 DataFrame 정리
pca_cols = ['pca_com1', 'pca_com2']
pca_df = pd.DataFrame(data=X_pca, columns=pca_cols)
pca_df['label'] = iris['target']
pca_df.head(2)
'''
pca_com1 pca_com2 label
0 -2.264703 0.480027 0
1 -2.080961 -0.674134 0
'''
# 시각화(원본 feature vs PCA 변환 결과 비교)
fig, ax = plt.subplots(ncols = 2)
# 왼쪽: 원본 feature (sepal length, sepal width)
sns.scatterplot(data = iris_df,
x = 'sepal length (cm)',
y = 'sepal width (cm)',
hue = 'label',
ax = ax[0])
# 오른쪽: PCA 결과 (주성분 1, 주성분 2)
sns.scatterplot(data=pca_df,
x='pca_com1',
y='pca_com2',
hue = 'label',
ax = ax[1])
plt.show()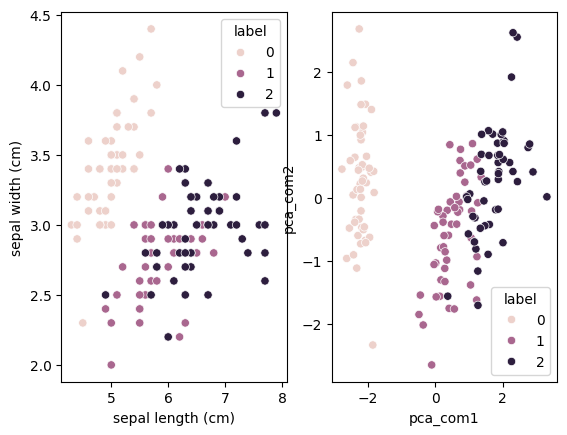
2. Association Rule
- 개념
- 추천 시스템, 장바구니 분석 등에서 활용
- 추천 알고리즘의 하나
- 규칙 형태: if A → B (A=선행, B=후행)
- 주요 용어
- Support (지지도): X와 Y가 함께 발생할 확률 → 빈발성 척도
- Confidence (신뢰도): X 발생 시 Y도 발생할 조건부 확률 → 효율성, 유효성 척도
- Lift (향상도): X와 Y가 독립적인지 여부 판단
- Lift = 1 → 독립적
- Lift > 1 → 양의 상관관계
- Lift < 1 → 음의 상관관계
- 예시
- Support(X=식빵·버터) = 3/10
- Support(Y=우유) = 4/10
- Support(X→Y) = 3/10
- Confidence = 1.0
- Lift = 2.5 → 양의 상관관계
2.1.알고리즘
2.1.1. Apriori 알고리즘
- 전제: “빈번한 아이템셋의 부분집합도 빈번하다”
- 단계적 후보 생성 → 지지도 낮은 규칙 제거
# Apriori 알고리즘 실습 (장바구니 분석)
# 1. 데이터 준비; 각 행(row)은 하나의 거래(transaction), 각 원소는 구매된 품목
data = np.array([
['식빵', '버터', '우유'],
['바게트빵', '소금', '올리브유'],
['식빵', '버터', '우유', '잼'],
['치즈케익', '바게트빵', '식빵'],
['식빵', '잼', '샐러드유'],
['치즈케익', '잼', '치즈'],
['치즈', '우유'],
['식빵'],
['식빵', '버터', '우유'],
['바게트빵']
], dtype=object)
# 2. 데이터를 희소행렬로 변환
from mlxtend.preprocessing import TransactionEncoder
trans_enc = TransactionEncoder()
trans_arr = trans_enc.fit_transform(data) # True/False 형태의 sparse matrix로 변환
df = pd.DataFrame(trans_arr, columns=trans_enc.columns_)
df.head(2)
'''
바게트빵 버터 샐러드유 소금 식빵 올리브유 우유 잼 치즈 치즈케익
0 False True False False True False True False False False
1 True False False True False True False False False False
'''
# 3. Apriori 알고리즘 적용
from mlxtend.frequent_patterns import apriori
# 최소 지지도(min_support=0.3, 즉 거래의 30% 이상에서 등장하는 아이템셋만 남김)
result = apriori(df, min_support=0.3, use_colnames=True)
result
'''
support itemsets
0 0.3 (바게트빵)
1 0.3 (버터)
2 0.6 (식빵)
3 0.4 (우유)
4 0.3 (잼)
5 0.3 (버터, 식빵)
6 0.3 (버터, 우유)
7 0.3 (우유, 식빵)
8 0.3 (버터, 우유, 식빵)
'''
# 4. 연관 규칙 생성
from mlxtend.frequent_patterns import association_rules
result_df = association_rules(result,
metric="confidence", # 신뢰도 사용
min_threshold=0.5, # 신뢰도가 50% 이상인 규칙만 생성
support_only=False) # 신뢰도 사용하니까 False로 두기
# lift 기준으로 정렬 (연관 강도가 높은 규칙 우선)
sort_df = result_df.sort_values(by = "lift", ascending=False)
sort_df.head()
'''
antecedents consequents antecedent support consequent support support confidence lift representativity leverage conviction zhangs_metric jaccard certainty kulczynski
8 (우유, 식빵) (버터) 0.3 0.3 0.3 1.00 3.333333 1.0 0.21 inf 1.000000 1.00 1.000000 1.000
9 (버터) (우유, 식빵) 0.3 0.3 0.3 1.00 3.333333 1.0 0.21 inf 1.000000 1.00 1.000000 1.000
2 (버터) (우유) 0.3 0.4 0.3 1.00 2.500000 1.0 0.18 inf 0.857143 0.75 1.000000 0.875
7 (버터, 식빵) (우유) 0.3 0.4 0.3 1.00 2.500000 1.0 0.18 inf 0.857143 0.75 1.000000 0.875
3 (우유) (버터) 0.4 0.3 0.3 0.75 2.500000 1.0 0.18 2.8 1.000000 0.75 0.642857 0.875
해석:
- {우유, 식빵} → {버터}, lift=3.33 → 우유와 식빵을 같이 산 고객은 버터도 함께 살 확률이 3.33배 높음
- {버터} → {우유, 식빵}, confidence=1.0 → 버터 구매자는 항상 우유+식빵을 같이 샀음
'''2.1.2. FP-Growth 알고리즘
- Apriori 개선 버전
- FP-Tree 구조 활용 → DB 접근 횟수 줄여 효율 ↑
# FP-Growth 알고리즘 실습
from mlxtend.frequent_patterns import fpgrowth
# 1. FP-Growth 적용
# - apriori와 마찬가지로 TransactionEncoder로 변환한 희소행렬 df를 입력
# - min_support=0.3 : 거래의 30% 이상에서 등장하는 아이템셋만 남김
result = fpgrowth(df, min_support=0.3, use_colnames=True)
# 2. 연관 규칙 생성
result_df = association_rules(result,
metric="confidence", # 신뢰도 사용
min_threshold=0.5,
support_only=False) # 신뢰도 사용하니까 False로 두기
# 3. lift 기준 정렬
sort_df = result_df.sort_values(by = "lift", ascending=False)
sort_df.head()
'''
antecedents consequents antecedent support consequent support support confidence lift representativity leverage conviction zhangs_metric jaccard certainty kulczynski
8 (우유, 식빵) (버터) 0.3 0.3 0.3 1.00 3.333333 1.0 0.21 inf 1.000000 1.00 1.000000 1.000
9 (버터) (우유, 식빵) 0.3 0.3 0.3 1.00 3.333333 1.0 0.21 inf 1.000000 1.00 1.000000 1.000
2 (버터) (우유) 0.3 0.4 0.3 1.00 2.500000 1.0 0.18 inf 0.857143 0.75 1.000000 0.875
7 (버터, 식빵) (우유) 0.3 0.4 0.3 1.00 2.500000 1.0 0.18 inf 0.857143 0.75 1.000000 0.875
3 (우유) (버터) 0.4 0.3 0.3 0.75 2.500000 1.0 0.18 2.8 1.000000 0.75 0.642857 0.875
''''LG U+ Why Not SW Camp 8기 > 학습 로그' 카테고리의 다른 글
| 공부 일지 #39 | GitHub & Sourcetree 시작하기 (0) | 2025.09.17 |
|---|---|
| 공부 일지 #38 | 머신러닝: 시계열 데이터 (1) | 2025.09.14 |
| 공부 일지 #36 | 머신러닝: 나이브베이즈와 군집분석(비지도) (0) | 2025.09.14 |
| 공부 일지 #35 | 머신러닝: 앙상블과 RandomForest, 교차검증 (0) | 2025.09.14 |
| 공부 일지 #34 | 머신러닝: 성능지표(ROC·AUC)와 Decision Tree (0) | 2025.09.11 |
