학습날짜: 2025.09.11
1. 시계열데이터의 특징
- 시계열 데이터?
: 연도별, 월별, 일별, 시별, 분별, 초별 등 균등한 간격으로 관측된 자료 의미함 - 분석 이유
: 시간 흐름에 따른 변화를 분석해서 미래 값 예측, 추세(Trend), 주기(Cyclic), 계절성(Seasonality) 파악하려는 것임 - 일반 데이터와 차이
- 시계열은 시간 자체가 주요 영향 요인
- 예) 통장에 백만원 넣어두면 날짜가 지남에 따라 이자가 붙음 → 어제와 오늘 데이터가 밀접한 상관성 가짐
- 데이터 형태
- POS 구매자료(불규칙 시차)
- 일별/주별/월별/분기별 등 규칙적 시차 데이터
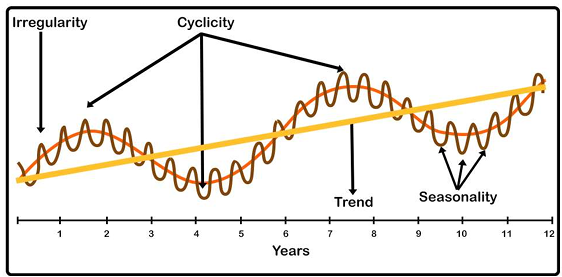
- 구성요소 (S(t) = T(t) + S(t) + C(t) + R(t))
- 추세(Trend, T) : 시간 따라 상승/하락 경향성
- 계절성(Seasonality, S) : 일·주·월·계절 단위로 반복되는 변동
- 순환(Cyclic, C) : 수년 단위의 장기 변동 (이론적 개념)
- 불규칙성(Random, R) : 설명 불가능한 우연 요인
- 분석 목적
- 과거 데이터의 패턴을 이용해 미래 예측
- 시계열 데이터는 독립적이지 않고, 가까운 시점일수록 상관성 강함
- 단, 정상성(stationarity) 확보가 필요함
- 정상성과 비정상성
- 대부분의 시계열 데이터는 비정상적임
- 정상성 데이터 = 평균, 분산 일정 → 백색잡음 특성 가짐
- 비정상 데이터는 그대로 모델에 넣으면 의미 없음 → 변환 필요

- 정상성 확인 방법
- ACF(자기상관) : 모든 상관성 확인
- PACF(부분자기상관) : 직접 경로 상관성만 확인
- 자기상관이 높으면 비정상 시계열 데이터로 판단
- Lagged value(지연값) 이용해 패턴 확인
2. 분석 방법
2.1. EDA
- 평활법(smoothing)
- 이동평균(SMA): window 이동하며 평균 → 단점: 시간 영향력 상쇄
- 지수이동평균(EWMA): 최근 데이터에 더 큰 가중치 → 트렌드 반영 상대적으로 빠름
- 분해법(decomposition)
- 데이터 = trend + seasonality + random 으로 분해
- trend 성분은 회귀분석 표본데이터로 활용 가능
2.2. 시계열 모형
2.2.1. AR(자기회귀모형)
- 현재 값 = 과거 값들의 함수
- lagged value 사용
- 입력 데이터는 정상시계열 필요
2.2.2. MA(이동평균모형)
- 현재 값 = 과거 오차들의 선형결합
- 백색잡음의 선형결합이므로, 항상 정상성 만족
2.2.3. ARIMA (Autoregressive Integrated Moving Average)
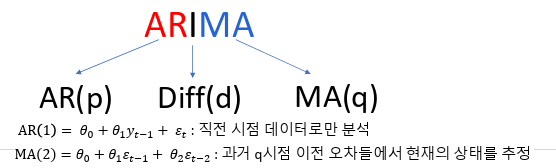
- AR + MA 결합 모형
- 대부분의 데이터는 비정상 → 차분(differencing) 통해 정상화 후 사용
- ARIMA(p, d, q) 형태
- p: AR 차수
- d: 차분 횟수
- q: MA 차수
- 차분 예시
- 1차 차분: Xt – Xt-1
- 2차 차분: Xt – Xt-2 (잘 안 씀, 데이터 왜곡 심함)
- 모형 해석 예시
- ARIMA(0, 1, 0) → 단순 1차 차분
- ARIMA(0, 1, 2) → IMA(1, 2) 모형에서 1차 차분 후 MA(2) 적용
- ARIMA(2, 1, 0) → ARI(2, 1) 모형에서 1차 차분 후 AR(2) 적용
# 1. 라이브러리 불러오기
!pip install pmdarima
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import pickle
from statsmodels.tsa.stattools import adfuller # ADF 검정
from pmdarima.arima import auto_arima # ARIMA 자동 파라미터 탐색
# 2. 데이터 불러오기
shampoo_df = pd.read_csv(path)
shampoo_df.head(2)
'''
Month Sales
0 1-01 266.0
1 1-02 145.9
'''
# 3. 정상성 검정 (ADF Test)
# 정상성 확인
def check_stationary(ts):
print("H0: 시계열이 정상성을 가지지 않는다.")
print("H1: 시계열이 정상성을 갖는다.")
adft = adfuller(ts, autolag="AIC")
print(f"통계량: {adft[0]}, p-value: {adft[1]}")
# 원 데이터 확인
check_stationary(shampoo_df['Sales'])
'''
H0: 시계열이 정상성을 가지지 않는다.
H1: 시계열이 정상성을 갖는다.
통계량: 3.060142083641181, p-value: 1.0
=> H0 채택 → 정상성 없음
'''
# 4. 차분으로 정상화
# 1차 차분
shampoo_df['Sales_diff'] = shampoo_df['Sales'].diff()
# 맨 처음 값(첫 번째 row)은 비교할 이전 값이 없으므로 결과가 하나가 NaN이 되기 때문에.
shampoo_df.dropna(inplace=True)
# 다시 정상성 검정
check_stationary(shampoo_df['Sales_diff'])
'''
H0: 시계열이 정상성을 가지지 않는다.
H1: 시계열이 정상성을 갖는다.
통계량: -7.249074055553854, p-value: 1.7998574141687034e-10
=> H1 채택 → 정상성 확보
'''
5. ARIMA 모델 적합 (auto_arima)
'''
p = [1,2,3]
d = [1,2,3]
q = [1,2,3]
for a,b,c in zip(p,d,q):
aic = arima(p,d,q)
# 이렇게 일일히 해야할 것을 auto_arima쓰면 알아서 해줌
'''
model = auto_arima(shampoo_df['Sales'],
start_p=0,
start_q = 0,
max_p=3,
max_q=3,
test='adf',
d=None, # 알아서 해달라는 의미
m = 1, # 1년 단위로 분석해라
seasonal=False,
trace = True, # 값 추적 허용
stepwise=True) # p,q 조합 허용
print(model.summary())
'''
Performing stepwise search to minimize aic
ARIMA(0,1,0)(0,0,0)[0] intercept : AIC=418.150, Time=0.02 sec
ARIMA(1,1,0)(0,0,0)[0] intercept : AIC=393.068, Time=0.04 sec
ARIMA(0,1,1)(0,0,0)[0] intercept : AIC=394.655, Time=0.12 sec
ARIMA(0,1,0)(0,0,0)[0] : AIC=416.790, Time=0.01 sec
ARIMA(2,1,0)(0,0,0)[0] intercept : AIC=389.136, Time=0.15 sec
ARIMA(3,1,0)(0,0,0)[0] intercept : AIC=389.780, Time=0.38 sec
ARIMA(2,1,1)(0,0,0)[0] intercept : AIC=389.277, Time=0.85 sec
ARIMA(1,1,1)(0,0,0)[0] intercept : AIC=387.783, Time=0.57 sec
ARIMA(1,1,2)(0,0,0)[0] intercept : AIC=inf, Time=0.97 sec
ARIMA(0,1,2)(0,0,0)[0] intercept : AIC=inf, Time=1.55 sec
ARIMA(2,1,2)(0,0,0)[0] intercept : AIC=inf, Time=1.02 sec
ARIMA(1,1,1)(0,0,0)[0] : AIC=394.574, Time=0.10 sec
Best model: ARIMA(1,1,1)(0,0,0)[0] intercept
Total fit time: 5.817 seconds
Note: AIC 가장 작은게 가장 잘 학습된 것!
'''
6. 모델 진단
model.plot_diagnostics(figsize=(12,8))
plt.show()
'''
1. 표준화 잔차 → 평균·분산 일정?
2. 잔차 히스토그램 → 정규성 확인
3. Q-Q plot → 정규성 확인
4. ACF plot → 잔차의 독립성 확인
'''
# 7. Train/Test 분리 & 예측
triaing_rate = 0.80
train = shampoo_df[:int(len(shampoo_df)*triaing_rate)]
test = shampoo_df[int(len(shampoo_df)*triaing_rate) :]
# train 데이터로 다시 모델 학습
model = auto_arima(train['Sales'],
start_p=0,
start_q = 0,
max_p=3,
max_q=3,
test='adf',
d=None, # 알아서 해달라는 의미
m = 1, # 1년 단위로 분석해라
seasonal=False,
trace = True, # 값 추적 허용
with_intercept='auto', # 상수항
stepwise=True) # p,q 조합 허용
'''
Note:
- seasonal=True 줘도 결과 비슷함 → ARIMA 한계일수도
- 선형 특성 때문에 예측이 단순 직선화됨
- 이를 보완하기 위해서는 sine + cosine을 이용해서 만들어진 trigomatric 모델을 쓸 수도 있음
- holt-winters model: 이게 훨씬 잘 맞음
'''
# test 구간 예측
y_pred = model.predict(n_periods=len(test))
pred_df = pd.DataFrame(y_pred, index=test.index, columns=['y_pred'])
# 결과 병합
result_df = pd.concat([test, pred_df], axis=1)
result_df.columns = ['Month', 'y', 'Sales_diff', 'y_pred']
# 8. 성능 평가 (RMSE)
# 모델 성능 평가: 1/n * (y-yhat) ^2
def rmse(y, ypred):
return np.sqrt(np.mean(np.square(y-ypred)))
rmse(result_df['y'], result_df['y_pred'])
# 35.58399697627928
# 9. 예측 결과 시각화
plt.figure(figsize=(20,6))
plt.grid(True)
plt.xlabel("Dates")
plt.ylabel("Sales_diff")
plt.plot(result_df["Month"], result_df["y"], c = "red")
plt.plot(result_df["Month"], result_df["y_pred"], c = 'blue')
plt.show()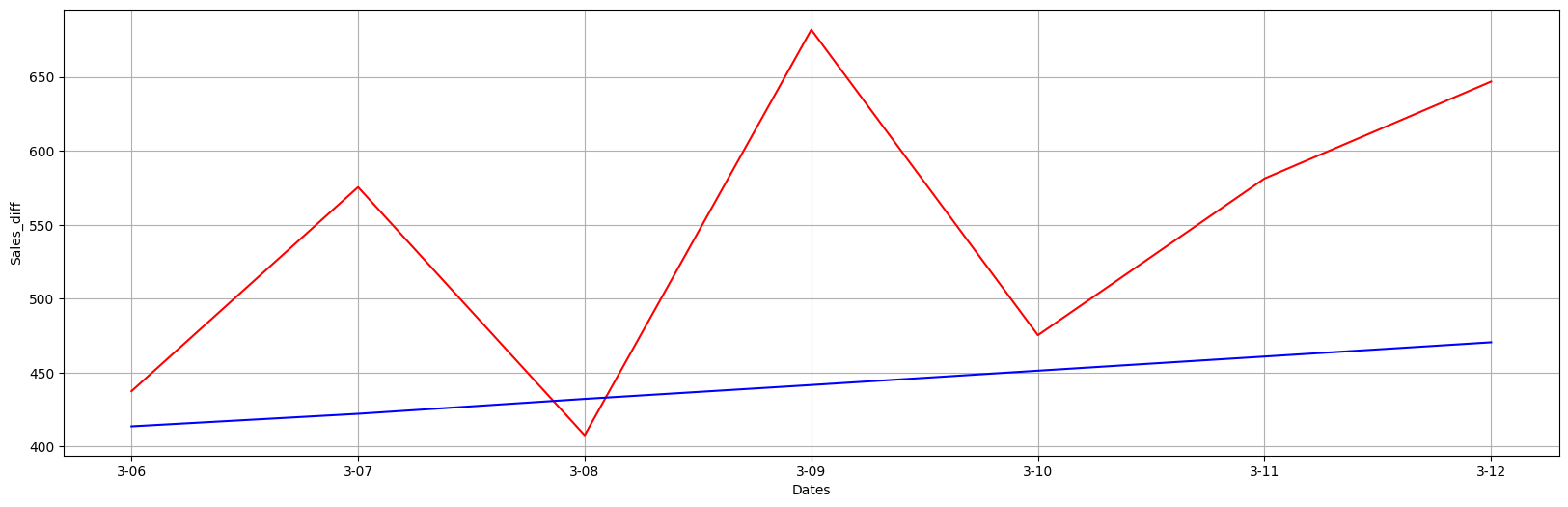
# 10. 모델 저장 & 로드
# 저장
filename = "/content/drive/MyDrive/ML/auto_arima_model.save"
pickle.dump(model, open(filename, 'wb'))
# 불러오기
loaded_model = pickle.load(open(filename, 'rb'))
y_pred = loaded_model.predict(n_periods=len(test))
'''
- 저장한 학습된 모델 load -> predict
- 이렇게 해서 모델을 서비스에 적용시킬 수 있음!
''''LG U+ Why Not SW Camp 8기 > 학습 로그' 카테고리의 다른 글
| 공부 일지 #40 | HTML과 CSS 배우기 (1) | 2025.09.21 |
|---|---|
| 공부 일지 #39 | GitHub & Sourcetree 시작하기 (0) | 2025.09.17 |
| 공부 일지 #37 | 머신러닝: 차원 축소와 추천 알고리즘 (0) | 2025.09.14 |
| 공부 일지 #36 | 머신러닝: 나이브베이즈와 군집분석(비지도) (0) | 2025.09.14 |
| 공부 일지 #35 | 머신러닝: 앙상블과 RandomForest, 교차검증 (0) | 2025.09.14 |
